Can someone tell me how to do this in Database?
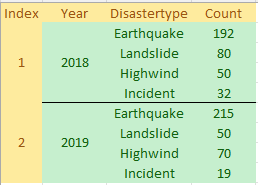
I've tried some sql like:
SELECT disastertype, YEAR(eventdate) as year,
COUNT(disastertype) AS disastertype_total
FROM v_disasterlogs_all
WHERE YEAR(eventdate) >= year(CURRENT_TIMESTAMP) - 4
GROUP BY YEAR(eventdate)
ORDER BY YEAR(eventdate) ASC
But, it only shows like this:
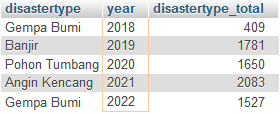
CodePudding user response:
include disastertype on our group by statement.
SELECT disastertype, YEAR(eventdate) as year,
COUNT(disastertype) AS disastertype_total
FROM v_disasterlogs_all
WHERE YEAR(eventdate) >= year(CURRENT_TIMESTAMP) - 4
GROUP BY YEAR(eventdate), disastertype
ORDER BY YEAR(eventdate) ASC
CodePudding user response:
I am assuming you want a count (the column index) to be associated with each unique year?
In this case, a possible solution in postgres will be as below.
select
dense_rank() over (order by date_part('year', (eventdate))) as index ,
date_part('year', (eventdate)) as year,
disastertype,
count(disastertype)
from
v_disaterlogs_all
where
date_part('year', (eventdate)) >= date_part('year', now()) - 4
group by
year,
disastertype
order by
year asc;
In postgres, I have used the function date_part to extract the year from the timestamp.
Working solution on dbfiddle.