I have a dataframe with the following columns. A sample here:
df = pd.DataFrame({'product_id' : [20,20,20,20,20,22,22,22,22,22], 'date' : ['2020-06','2020-07','2020-08','2020-09',
'2020-10','2020-06','2020-07','2020-08','2020-09',
'2020-10'],'real': [1.2,3,4,5,1,1.5,2.9,5,6,1], 'pred': [1.3,4,4,5.1,1.2,1.5,3,6,5,1.5]})
And I want to calculate the MSE:
for game_id in df['product_id'].unique():
pred_g = df.query(f"product_id == '{game_id}'")
print(game_id, " MAE = ", mse(pred_g["real"], pred_g["pred"]))
I created a mse function directly:
def mse(actual, predicted):
actual = np.array(actual)
predicted = np.array(predicted)
differences = np.subtract(actual, predicted)
squared_differences = np.square(differences)
return squared_differences.mean()
And it is returning only NaN values for each product_id:
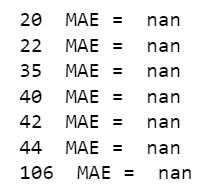
If I try to calculate it with the Sklearn function, then I got the following error:
ValueError: Found array with 0 sample(s) (shape=(0,)) while a minimum of 1 is required.
I have checked both x and y variables and both of them have the same shape and are not empty.
What can it be happening? I am quite confunsed.
CodePudding user response:
IIUC, you wan use GroupBy.var:
df['real'].sub(df['pred']).groupby(df['product_id']).var(ddof=0)
output:
product_id
20 0.1336
22 0.4376
dtype: float64
Manual computation:
s = df['real'].sub(df['pred'])
s.groupby(df['product_id']).apply(lambda x: x.sub(x.mean()).pow(2).mean())
CodePudding user response:
I tried your code and I am not getting any error.
import pandas as pd
import numpy as np
df = pd.DataFrame({'product_id' : [20,20,20,20,20,22,22,22,22,22], 'date' : ['2020-06','2020-07','2020-08','2020-09',
'2020-10','2020-06','2020-07','2020-08','2020-09',
'2020-10'],'real': [1.2,3,4,5,1,1.5,2.9,5,6,1], 'pred': [1.3,4,4,5.1,1.2,1.5,3,6,5,1.5]})
def mse(actual, predicted):
actual = np.array(actual)
predicted = np.array(predicted)
differences = np.subtract(actual, predicted)
squared_differences = np.square(differences)
return squared_differences.mean()
for game_id in df['product_id'].unique():
pred_g = df.query(f"product_id == '{game_id}'")
print(game_id, " MAE = ", mse(pred_g["real"], pred_g["pred"]))
Output:
20 MAE = 0.21200000000000002
22 MAE = 0.45199999999999996
CodePudding user response:
Use sklearn.metrics.mean_squared_error per groups:
from sklearn.metrics import mean_squared_error
s = (df.groupby('product_id')
.apply(lambda x: mean_squared_error(x['real'], x['pred'], squared=False)))
print (s)
product_id
20 0.460435
22 0.672309
dtype: float64
Or count it manually:
s = df['pred'].sub(df['real']).pow(2).groupby(df['product_id']).mean().pow(0.5)
print (s)
product_id
20 0.460435
22 0.672309
dtype: float64