Fill only last among of consecutive NaN in Pandas by mean of previous and next valid values. If one NaN, then fill with mean of next and previous. If two consecutive NaN, impute second one with mean of next and previous valid values.
Series:
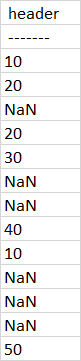
expected output:
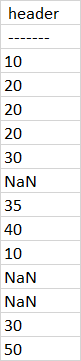
CodePudding user response:
Idea is remove consecutive missing values without last, then use interpolate and assign back last missing value by condition:
m = df['header'].isna()
mask = m & ~m.shift(-1, fill_value=False)
df.loc[mask, 'header'] = df.loc[mask | ~m, 'header'].interpolate()
print (df)
header
0 10.0
1 20.0
2 20.0
3 20.0
4 30.0
5 NaN
6 35.0
7 40.0
8 10.0
9 NaN
10 NaN
11 30.0
12 50.0
Details:
print (df.assign(m=m, mask=mask))
header m mask
0 10.0 False False
1 20.0 False False
2 20.0 True True
3 20.0 False False
4 30.0 False False
5 NaN True False
6 35.0 True True
7 40.0 False False
8 10.0 False False
9 NaN True False
10 NaN True False
11 30.0 True True
12 50.0 False False
print (df.loc[mask | ~m, 'header'])
0 10.0
1 20.0
2 NaN
3 20.0
4 30.0
6 NaN
7 40.0
8 10.0
11 NaN
12 50.0
Name: header, dtype: float64
Solution for interpolate per groups is:
df.loc[mask, 'header'] = df.loc[mask | ~m, 'header'].groupby(df['groups'])
.transform(lambda x: x.interpolate())
CodePudding user response:
You can try:
s = df['header']
m = s.isna()
df['header'] = s.ffill().add(s.bfill()).div(2).mask(m&m.shift(-1, fill_value=False))
output and intermediates:
header output ffill bfill m m&m.shift(-1)
0 10.0 10.0 10.0 10.0 False False
1 20.0 20.0 20.0 20.0 False False
2 NaN 20.0 20.0 20.0 True False
3 20.0 20.0 20.0 20.0 False False
4 30.0 30.0 30.0 30.0 False False
5 NaN NaN 30.0 40.0 True True
6 NaN 35.0 30.0 40.0 True False
7 40.0 40.0 40.0 40.0 False False
8 10.0 10.0 10.0 10.0 False False
9 NaN NaN 10.0 50.0 True True
10 NaN NaN 10.0 50.0 True True
11 NaN 30.0 10.0 50.0 True False
12 50.0 50.0 50.0 50.0 False False