I have a table like this:
date type value
2021-02-03 a 150
2021-02-04 b 150
2021-02-05 c 150
I want to divide the value into three rows and create a new column called category which is filled by x, y, and z respectively.
The desired table is like this:
date type value category
2021-02-03 a 50 x
2021-02-03 a 50 y
2021-02-03 a 50 z
2021-02-04 b 50 x
2021-02-04 b 50 y
2021-02-04 b 50 z
2021-02-05 c 50 x
2021-02-05 c 50 y
2021-02-05 c 50 z
how can I make it in python?
CodePudding user response:
If the data is really that specific I would suggest some approach with generators and pd.DataFrame.explode().
# sample data
data = [
{"date": "2021-02-03", "type": "a", "value": 150},
{"date": "2021-02-04", "type": "b", "value": 150},
{"date": "2021-02-05", "type": "c", "value": 150},
]
df = pd.DataFrame(data)
# how much groups you are going to divide the columns "value" for
groups = 3
# this will create a list from the value integer, where each element in list is the exactly amount needed to explode afterwards, in this example [50, 50, 50]
df["value"] = df["value"].apply(lambda x: [x / groups for _ in range(groups)])
# explode the list into n rows
df = df.explode("value", ignore_index=True)
# categories generator
def categories_generator():
categories = ["x", "y", "z"]
while True:
for category in categories:
yield category
c_gen = categories_generator()
# create a new columns from a pd.Series() where you iteract through the generator
df["category"] = pd.Series([next(c_gen) for _ in range(len(df))])
CodePudding user response:
The question required to replicate a row with three rows equal in date and type but different in value. The value should be partitioned into equal values for three categories. A quick solution can be:
import numpy as np
import pandas as pd
L = [
["2021-02-03", "a", 150],
["2021-02-04", "b", 150],
["2021-02-05", "c", 150],
]
header = ["date", "type", "value"]
df = pd.DataFrame(L, columns=header)
print(df)
newData = [
{**df.iloc[i].copy(), "value": df.iloc[i, 2] / 3.0, "category": cat}
for cat in ["x", "y", "z"] # Loop on each category.
for i in range(len(df)) # Loop on each row.
]
newDf = pd.DataFrame(newData, columns=header ["category"])
# Sort the rows by date and category inplace.
newDf.sort_values(by=["date", "category"], inplace=True)
print(newDf)
The original records are:
date type value
0 2021-02-03 a 150
1 2021-02-04 b 150
2 2021-02-05 c 150
The output should be:
date type value category
0 2021-02-03 a 50.0 x
3 2021-02-03 a 50.0 y
6 2021-02-03 a 50.0 z
1 2021-02-04 b 50.0 x
4 2021-02-04 b 50.0 y
7 2021-02-04 b 50.0 z
2 2021-02-05 c 50.0 x
5 2021-02-05 c 50.0 y
8 2021-02-05 c 50.0 z
It is worth noting that, if it is required to increase the number of categories, the value 3.0 in df.iloc[i, 2] / 3.0 should be modified. Also, if the question required the value to be an integer value, use int(df.iloc[i, 2] / 3.0) instead of df.iloc[i, 2] / 3.0.
CodePudding user response:
Use this
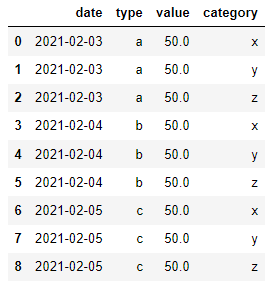
# initialize the number of categories for each type
n = 3
# repeat df n times
df = df.loc[df.index.repeat(n)]
# divide values in value column
df['value'] /= n
# insert category column
df['category'] = ['x','y','z'] * n
# reset the index to fix duplicate indices
df = df.reset_index(drop=True)
df
CodePudding user response:
try this:
out = df.assign(category='xyz', value=df.value.div(3))
out.category = out.category.apply(list)
out = out.explode('category')
print(out)
>>>
date type value category
0 2021-02-03 a 50.0 x
0 2021-02-03 a 50.0 y
0 2021-02-03 a 50.0 z
1 2021-02-04 b 50.0 x
1 2021-02-04 b 50.0 y
1 2021-02-04 b 50.0 z
2 2021-02-05 c 50.0 x
2 2021-02-05 c 50.0 y
2 2021-02-05 c 50.0 z