Index a b c d e f g h i j zeros
0 9 -8 -3 0 0 3 0 0 0 3 5
1 0 0 8 2 -5 0 0 -5 4 12 4
2 0 0 3 13 0 -9 11 -2 5 0 4
3 0 0 1 12 1 0 11 -6 1 0 4
4 0 0 1 11 0 -3 0 -2 -6 12 4
5 0 0 1 0 6 -5 0 -5 3 7 4
6 0 0 0 12 -6 0 2 7 -1 2 4
7 0 0 0 0 5 -5 5 0 8 7 5
8 0 0 0 0 0 0 0 0 0 0 10
9 0 0 -2 12 0 -1 0 3 6 3 4
10 0 0 -4 3 -4 0 0 4 -1 1 4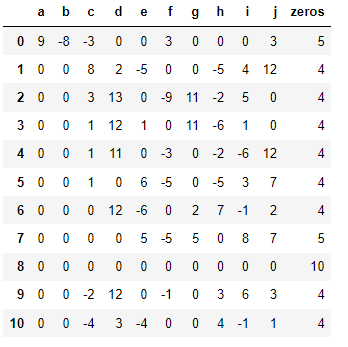
I want to sort my dataframe based on highest zeros which can be done easily by sorting using zeros column. but in case of 1st adn 7 row i have the same number of zeros. In this case i am suppose to look at the order of occurance of 0's from left of the dataframe to the right (from column a to column j) which should give me the output as shown below: basically, when you look at the order of zeros you will see that in the result i have 4 columns containing zeros being placed first out of two rows contianing zeros = 5.
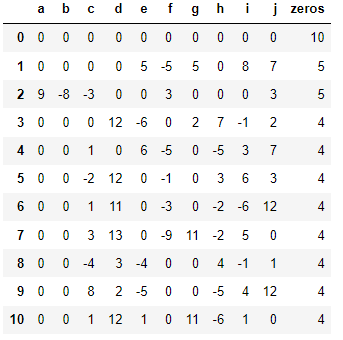
CodePudding user response:
You can create a weight column:
df['weight'] = (df.loc[:, 'a':'j'].eq(0)
.mul((2 ** np.arange(len(df.columns) - 1))[::-1])
.sum(axis=1))
Output:
>>> df.sort_values(['zeros', 'pri'], ascending=False)
a b c d e f g h i j zeros weight
0 9 -8 -3 0 0 3 0 0 0 3 5 110
1 0 0 8 2 -5 0 0 -5 4 12 4 792
2 0 0 3 13 0 -9 11 -2 5 0 4 801
3 0 0 1 12 1 0 11 -6 1 0 4 785
4 0 0 1 11 0 -3 0 -2 -6 12 4 808
5 0 0 1 0 6 -5 0 -5 3 7 4 840
6 0 0 0 12 -6 0 2 7 -1 2 4 912
7 0 0 0 0 5 -5 5 0 8 7 5 964
8 0 0 0 0 0 0 0 0 0 0 10 1023
9 0 0 -2 12 0 -1 0 3 6 3 4 808
10 0 0 -4 3 -4 0 0 4 -1 1 4 792
Step by step:
>>> out = df.loc[:, 'a':'j'].eq(0)
a b c d e f g h i j
0 False False False True True False True True True False
1 True True False False False True True False False False
2 True True False False True False False False False True
3 True True False False False True False False False True
4 True True False False True False True False False False
5 True True False True False False True False False False
6 True True True False False True False False False False
7 True True True True False False False True False False
8 True True True True True True True True True True
9 True True False False True False True False False False
10 True True False False False True True False False False
>>> out = out.mul((2 ** np.arange(len(df.columns) - 1))[::-1])
a b c d e f g h i j
0 0 0 0 64 32 0 8 4 2 0
1 512 256 0 0 0 16 8 0 0 0
2 512 256 0 0 32 0 0 0 0 1
3 512 256 0 0 0 16 0 0 0 1
4 512 256 0 0 32 0 8 0 0 0
5 512 256 0 64 0 0 8 0 0 0
6 512 256 128 0 0 16 0 0 0 0
7 512 256 128 64 0 0 0 4 0 0
8 512 256 128 64 32 16 8 4 2 1
9 512 256 0 0 32 0 8 0 0 0
10 512 256 0 0 0 16 8 0 0 0
>>> out = out.sum(axis=1)
0 110
1 792
2 801
3 785
4 808
5 840
6 912
7 964
8 1023
9 808
10 792
dtype: int64