I'm looking for a formula that count the number of differents cell value in a range, among the duplicate.
let me explain : I have the "File Number" in column A (one ID for a groups of client that book together, a family) Taxi ID in column B (ID use for each Taxi) There can be multiple fileNumber in one taxi (2groups take the same taxi) My Goal is to know how many group is there in one taxi.
The lines are All the client, so the file number is duplicate (times the number of client by group).
My idea was to use COUNTIFS() =COUNTIFS(A$2:A$1003,"<>"&A2;B$2:B$1003,B2) 1 but if i have duplicate, like a 3 person family, it will count the file 3 times.
Here is an example in csv, basicaly in this case the function must return 1 for the "taxi T344718" and 3 for the taxi T444718
file Number;Taxi ID;client name
194293422;T344718;name 1
194293422;T344718;name 2
194293422;T344718;name 3
194293422;T344718;name 4
194293422;T344718;name 5
205107347;T444718;name 6
17103917;T444718;name 7
17103917;T444718;name 8
17103917;T444718;name 9
124162966;T444718;name 10
124162966;T444718;name 11
CodePudding user response:
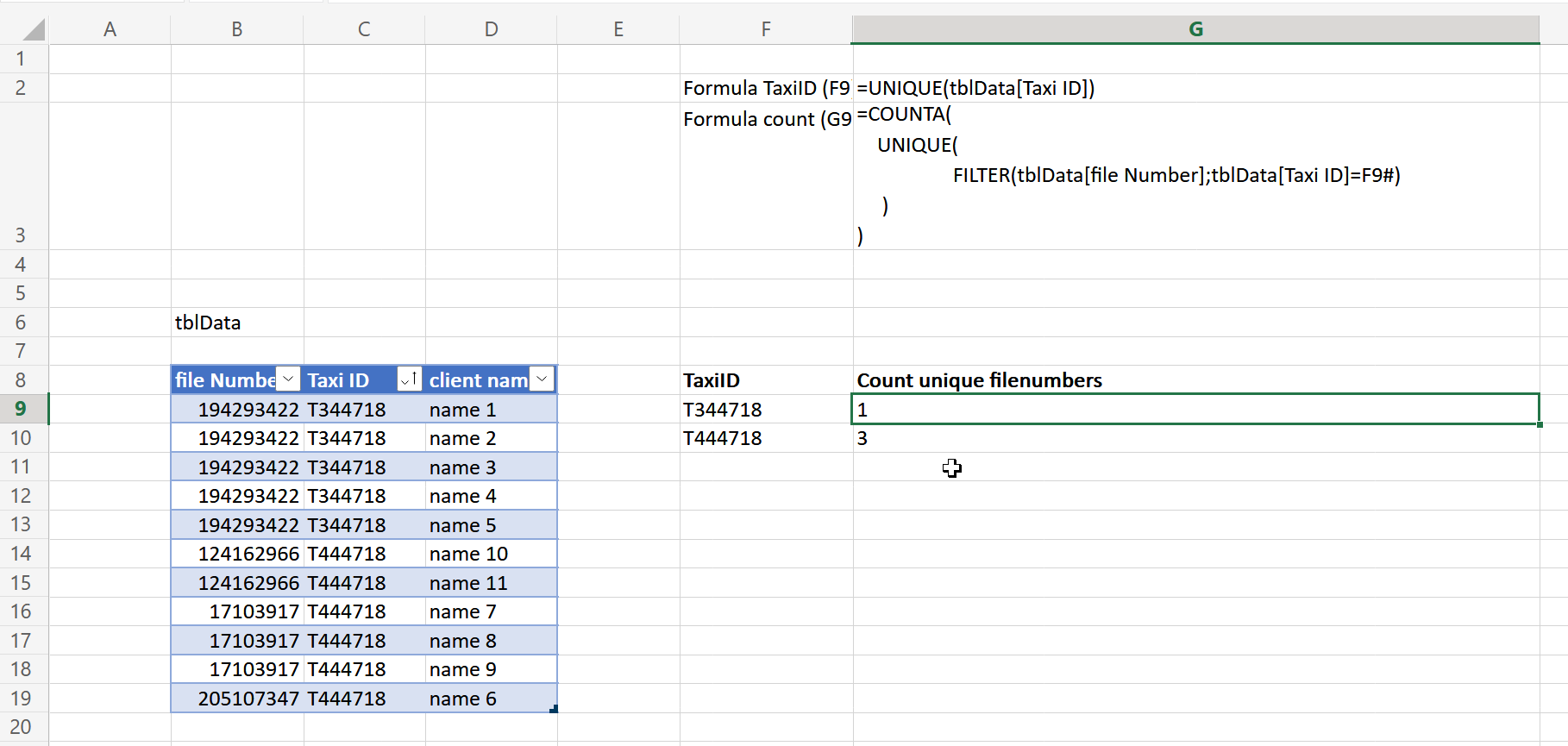
You can use the following two formulas (using Excel 365 formulas):
To retrieve the a list of unique Taxi IDs:
=UNIQUE(tblData[Taxi ID])
And then to count the unique filenumbers per taxi - per TaxiID
=COUNTA(
UNIQUE(
FILTER(tblData[file Number],tblData[Taxi ID]=F9#)
)
)
I named the table tblData
CodePudding user response:
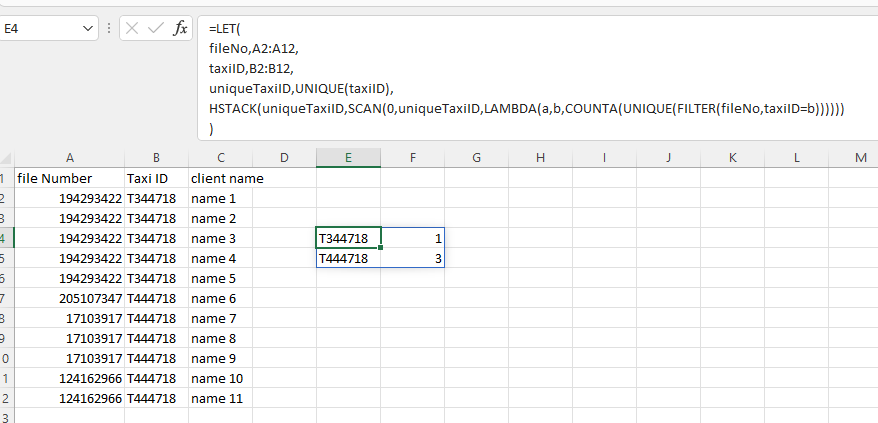
Just experimenting with this to see if I could do it in a single formula using recent additions to Excel 365:
LET(
fileNo,A2:A12,
taxiID,B2:B12,
uniqueTaxiID,UNIQUE(taxiID),
HSTACK(uniqueTaxiID,SCAN(0,uniqueTaxiID,LAMBDA(a,b,COUNTA(UNIQUE(FILTER(fileNo,taxiID=b))))))
)
Note Scan examples normally show it used a an accumulator, but you can use any expression you like as far as I can see.