typical report data is like this,
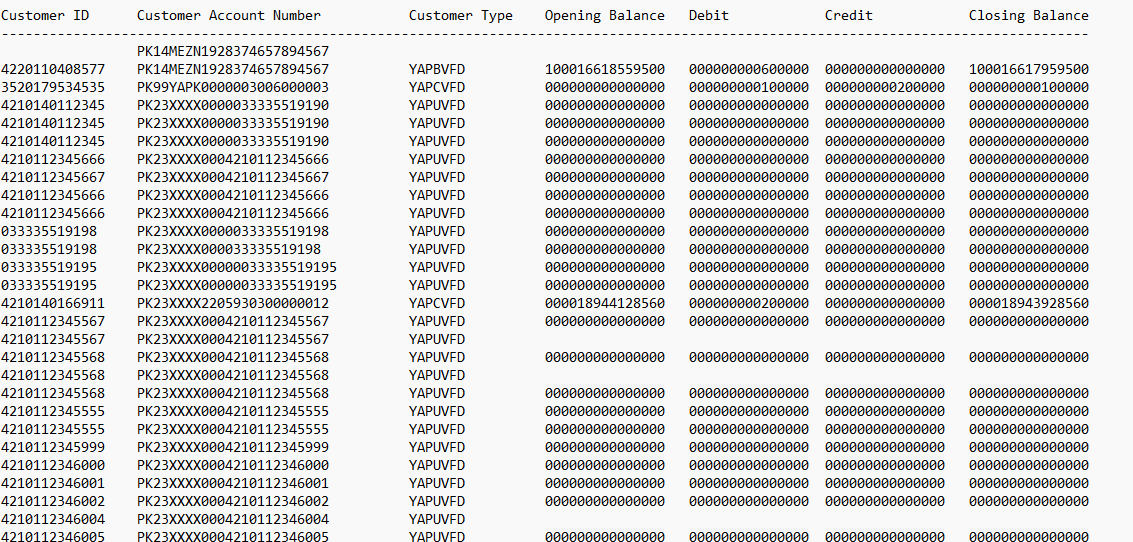
A simple approach that i wanted to follow was to use space as a delimeter but the data is not in a well structured manner
CodePudding user response:
read the first line of the file and split each column by checking if there is more than 1 whitespace. In addition to that you count how long each column is. after that you can simply go through the other rows containing data and extract the information, by checking the length of the column you are at
(and please don't put images of text into stackoverflow, actual text is better)
EDIT: python implementation:
import pandas as pd
import re
file = "path/to/file.txt"
with open("file", "r") as f:
line = f.readline()
columns = re.split(" ", line)
column_sizes = [re.finditer(column, line).__next__().start() for column in columns]
column_sizes.append(-1)
# ------
f.readline()
rows = []
while True:
line = f.readline()
if len(line) == 0:
break
elif line[-1] != "\n":
line = "\n"
row = []
for i in range(len(column_sizes)-1):
value = line[column_sizes[i]:column_sizes[i 1]]
row.append(value)
rows.append(row)
columns = [column.strip() for column in columns]
df = pd.DataFrame(data=rows, columns=columns)
print(df)
df.to_excel(file.split(".")[0] ".xlsx")
CodePudding user response:
you can use google lens to get your data out of this picture then copy and paste to excel file. the easiest way.
or first convert this into pdf then use google lens. go to file scroll to print option in print setting their is an option of MICROSOFT PRINT TO PDF select that and press print it will ask you for location then give it and use it