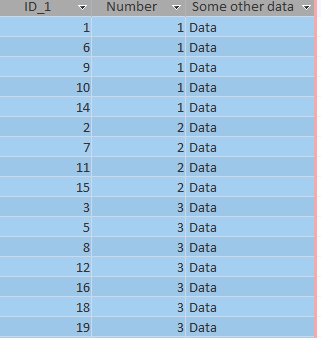
I'm working with an Access database and have two tables:
| ID_1 | Number | Some other data |
|---|---|---|
| 1 | 1 | Data |
| 2 | 2 | Data |
| 3 | 3 | Data |
| 4 | 4 | Data |
| 5 | 3 | Data |
| 6 | 1 | Data |
| 7 | 2 | Data |
| 8 | 3 | Data |
| 9 | 1 | Data |
| 10 | 1 | Data |
| 11 | 2 | Data |
| 12 | 3 | Data |
| 13 | 4 | Data |
| 14 | 1 | Data |
| 15 | 2 | Data |
| 16 | 3 | Data |
| 17 | 4 | Data |
| 18 | 3 | Data |
| 19 | 3 | Data |
| ID_2 | Number | Some other data |
|---|---|---|
| 1 | 3 | Data |
| 2 | 1 | Data |
| 3 | 2 | Data |
| 4 | 3 | Data |
| 5 | 2 | Data |
As you see, both tables have duplicate data. I need a query that would select all the records in the first table that match each of the records in the second, they are related by Number field. It's also necessary that these records aren't repeated (that is, that the query doesn't repeat values when selecting). For the given example I should get this result:
| ID | ID_1 | Number | Some other data |
|---|---|---|---|
| 1 | 3 | 3 | Data |
| 2 | 5 | 3 | Data |
| 3 | 8 | 3 | Data |
| 4 | 12 | 3 | Data |
| 5 | 16 | 3 | Data |
| 6 | 18 | 3 | Data |
| 7 | 19 | 3 | Data |
| 8 | 1 | 1 | Data |
| 9 | 6 | 1 | Data |
| 10 | 9 | 1 | Data |
| 11 | 10 | 1 | Data |
| 12 | 14 | 1 | Data |
| 13 | 2 | 2 | Data |
| 14 | 7 | 2 | Data |
| 15 | 11 | 2 | Data |
| 16 | 15 | 2 | Data |
I was thinking that maybe I could use Join, but I still don't know how; tried Where, but also didn't find a use for it. Could you please help me with that?
CodePudding user response:
MySql DB data structure
create table tbl1(ID_1 serial, Number int);
create table tbl2(ID_2 serial, Number int);
insert into tbl1(Number) values (1),(2),(3),(4),(3),(1),(2),(3),(1),(1),(2),(3),(4),(1),(2),(3),(4),(3),(3);
insert into tbl2(Number) values (3),(1),(2),(3),(2);
- query (with s), needed to remove duplicates
- the window function count(tbl1.Number) OVER(PARTITION BY Number) sorts the result for us by the count of matched numbers
- the @rownum variable is needed to count rows
with s as (select distinct Number from tbl2),
f as (select ID_1,tbl1.Number from tbl1 left join s on
(tbl1.Number=s.Number) where s.Number is not null order by
count(tbl1.Number) OVER(PARTITION BY Number) desc)
select @rownum := @rownum 1 AS ID,ID_1,Number from f, (SELECT @rownum := 0) r;
results
------ ------ --------
| ID | ID_1 | Number |
------ ------ --------
| 1 | 3 | 3 |
| 2 | 5 | 3 |
| 3 | 8 | 3 |
| 4 | 12 | 3 |
| 5 | 16 | 3 |
| 6 | 18 | 3 |
| 7 | 19 | 3 |
| 8 | 1 | 1 |
| 9 | 6 | 1 |
| 10 | 9 | 1 |
| 11 | 10 | 1 |
| 12 | 14 | 1 |
| 13 | 2 | 2 |
| 14 | 7 | 2 |
| 15 | 11 | 2 |
| 16 | 15 | 2 |
------ ------ --------
CodePudding user response:
I don't see where you're generating your output ID field from - or where you're picking your Data field from so here's the best guess.
SELECT Table1.ID_1, Table1.Number, Table1.[Some other data]
FROM Table1
WHERE (Table1.Number In (SELECT Number From Table2))
ORDER BY Table1.Number, Table1.ID_1;
Looks like this: