I have the follow set of data:
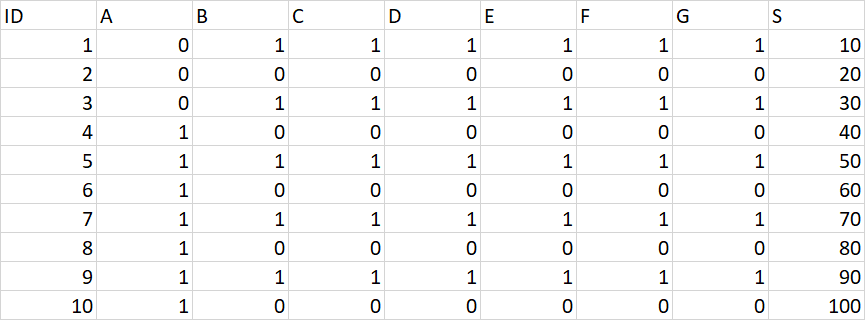 Using R and tidyverse if possible I would like to sum column S based upon a condition on other columns. If my variable
Using R and tidyverse if possible I would like to sum column S based upon a condition on other columns. If my variable
condition_columns = c('A', 'B')
The output I am after is a data frame containing

Where the 490 is obtained by summing column S only when A=1 and the 250 comes from summing column S when B=1.
Could anyone suggest a tidyverse way of doing it? Thank you, Phil,
CodePudding user response:
You can do this using summarize(across())
summarize(df, across(all_of(condition_columns), ~sum(S[.x==1])))
Output:
A B
1 490 250
Input:
structure(list(ID = 1:10, A = c(0, 0, 0, 1, 1, 1, 1, 1, 1, 1),
B = c(1, 0, 1, 0, 1, 0, 1, 0, 1, 0), S = c(10, 20, 30, 40,
50, 60, 70, 80, 90, 100)), class = "data.frame", row.names = c(NA,
-10L))
CodePudding user response:
You may use the following (easy to understand) code :
df %>%
summarise(A = sum(A*S),
B = sum(B*S))
Output:
A B
1 490 250