I have the following table:
id date cid birth_place location
1 2022-01-01 1 France Germany
2 2022-01-30 1 France France
3 2022-01-25 2 Spain Spain
4 2022-01-12 3 France France
5 2022-02-01 4 England Italy
6 2022-02-12 1 France France
7 2022-03-05 5 Spain England
8 2022-03-08 2 Spain Spain
9 2022-03-15 2 Spain Spain
10 2022-03-30 5 Spain Italy
11 2022-03-22 4 England England
12 2022-03-22 3 France England
I want to trunc date to month and then group by date and count distinct cid (customer id) based on location with a condition. The condition is if the customer's location within a given month is equal to their birthplace, then they are counted (where birth_place = location). Check my desired output:
date location count
2022-01-01 France 2
2022-01-01 Spain 1
2022-02-01 Italy 1
2022-02-01 France 1
2022-03-01 Spain 1
2022-03-01 England 3
cid 1 in 2022-01-01 had a location = birth_place, and no other customer had Germany as location in that time period, hence there is no Germany in my desired output location.
Edit: last row had an incorrect value, so I fixed it.
Edit: another view to further explain what I want to achieve. Hope this helps.
id date cid birth_place location | (I want to count distinct cids grouped by trunc('month', date) based on these values)
1 2022-01-01 1 France Germany | France (cid 1 has location France in Jan)
2 2022-01-30 1 France France | France
3 2022-01-25 2 Spain Spain | Spain
4 2022-01-12 3 France France | France
5 2022-02-01 4 England Italy | Italy (cid 4 has only location Italy in Feb and no England, so Italy is taken)
6 2022-02-12 1 France France | France
7 2022-03-05 5 Spain England | England (cid 5 has two locations that are not Spain, so the first one that the query sees is simply taken)
8 2022-03-08 2 Spain Spain | Spain
9 2022-03-15 2 Spain Spain | Spain
10 2022-03-30 5 Spain Italy | England
11 2022-03-22 4 England England | England
12 2022-03-22 3 France England | England
CodePudding user response:
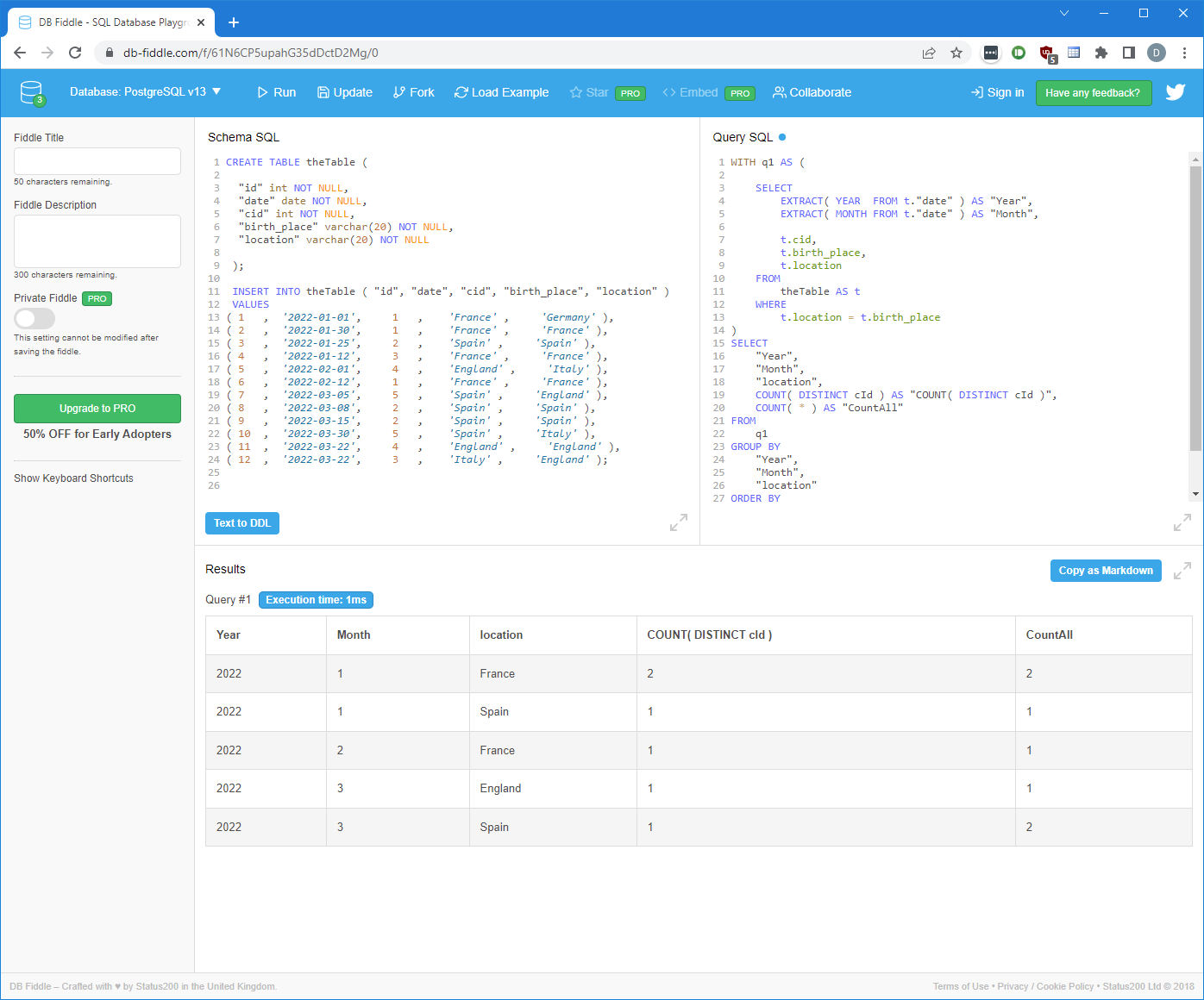
WITH q1 AS (
SELECT
EXTRACT( YEAR FROM t."date" ) AS "Year",
EXTRACT( MONTH FROM t."date" ) AS "Month",
t.cid,
t.birth_place,
t.location
FROM
theTable AS t
WHERE
t.location = t.birth_place
)
SELECT
"Year",
"Month",
"location",
COUNT( DISTINCT cId ) AS "COUNT( DISTINCT cId )",
COUNT( * ) AS "CountAll"
FROM
q1
GROUP BY
"Year",
"Month",
"location"
ORDER BY
"Year",
"Month",
"location"
CodePudding user response:
Simply:
SELECT date_trunc('month', date)::date AS date, location
, count(DISTINCT cid) AS count
FROM tbl
WHERE birth_place = location
GROUP BY 1, 2
ORDER BY 1, 2; -- optional
db<>fiddle here
CodePudding user response:
My approach would be using case...when within a count. That way it works with or without a where filter and therefore allows other aggregates of the data in the same query in the future.
SELECT
date_trunc('month', date)::date AS date, t.location
, count(distinct (case when t.location=t.birth_place then t.cid else null end)) as "count"
FROM theTable AS t
WHERE t.location=t.birth_place
GROUP BY date_trunc('month', date)::date, t.location