I'm trying to write my first ever scraper and I'm facing a problem. all of the tutorials I've watched of course mention Tags in order to kind of catch the part you want to scrape and they mention something like this, or this is actually my code thus far, I'm trying to scrape the title, date, and country of each story:
import requests
import csv
from bs4 import BeautifulSoup
from itertools import zip_longest
result = requests.get("https://www.cdc.gov/globalhealth/healthprotection/stories-from-the-
field/stories-by-country.html?Sort=Date::desc")
source = result.content
soup = BeautifulSoup(source,"lxml")
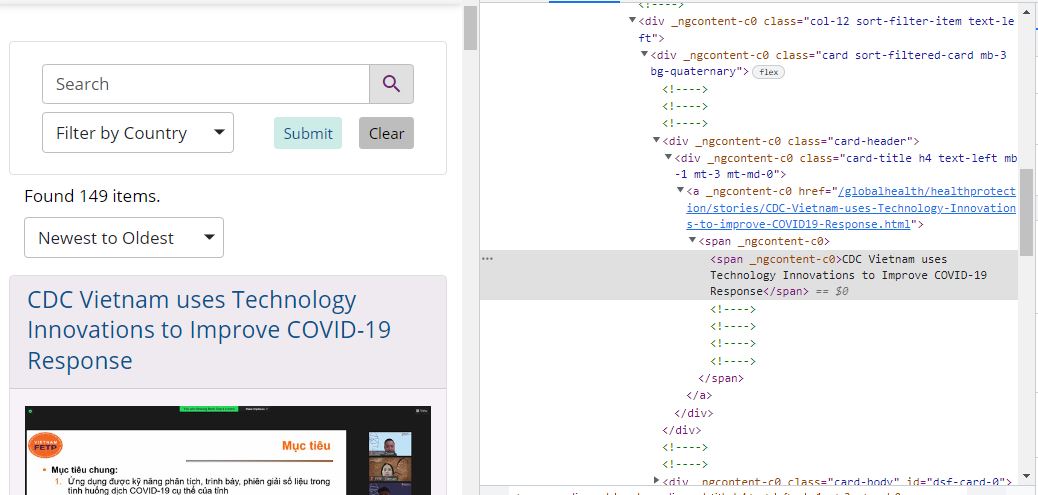
--------------------------NOW COMES MY PROBLEM------------------------------------------ when I start looking to scrape the title it in a CDC Vietnam uses Technology Innovations to Improve COVID-19 Response like this!
When I try the code I learned :
title = soup.find_all("span__ngcontent-c0",{"class": ##I don't know what goes here!})
of course it doesn't work. I have searched and found this _ngcontent-c0 is actually angular but I don't know how to scrape it! Any help?
CodePudding user response:
This web needs javascript to render all content you want to scrape.
It calls API to get all content. Just request this API.
You need to do something like this:
import requests
result = requests.get(
"https://www.cdc.gov/globalhealth/healthprotection/stories-from-the-field/dghp-stories-country.json")
for item in result.json()["items"]:
print("Title: " item["Title"])
print("Date: " item["Date"][0:10])
print("Country: " ','.join(item["Country"]))
print()
OUTPUT:
Title: System Strengthening – A One Health Approach
Date: 2016-12-12
Country: Kenya,Multiple
Title: Early Warning Alert and Response Network Put the Brakes on Deadly Diseases
Date: 2016-12-12
Country: Somalia,Syria
I hope I have been able to help you.