dput of the input dataframe :
structure(list(Entity = c("A", "A", "A", "A", "A", "A", "A",
"A", "A", "A", "B", "B", "B", "B", "B", "B", "B", "B", "B", "B"
), Date = structure(c(1640995200, 1641081600, 1641168000, 1641254400,
1641340800, 1641427200, 1641513600, 1641600000, 1641686400, 1641772800,
1640995200, 1641081600, 1641168000, 1641254400, 1641340800, 1641427200,
1641513600, 1641600000, 1641686400, 1641772800), tzone = "UTC", class = c("POSIXct",
"POSIXt")), Test = c("Y", "Y", "N", "Y", "N", "N", "Y", "Y",
"Y", "Y", "Y", "Y", "N", "Y", "N", "N", "Y", "Y", "Y", "Y"),
Value = c(5, 10, 5, 10, 10, 5, 5, 5, 5, 20, 10, 10, 5, 20,
20, 5, 5, 20, 20, 20), COUNTER = c(1L, 2L, 3L, 4L, 5L, 6L,
7L, 8L, 9L, 10L, 1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L)), class = c("tbl_df",
"tbl", "data.frame"), row.names = c(NA, -20L))
I would like to get a final dataframe that shows running 3 day average per entity where Test = 'Y'. For ex., based on the below screenshot,
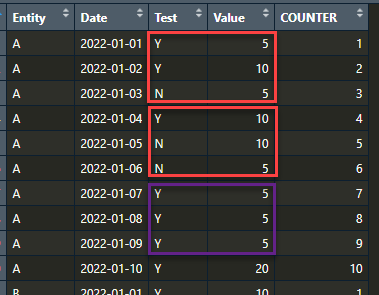
the running averages for the entity A would be:
Entity Counter_Running_avg Running_Avg
A 1 7.5 (15/2)
A 2 10 (10/1)
A 3 5 (15/3) and so on..
I began by writing the below code but this is not what I need...
dt %>%
arrange(Entity, Date) %>%
group_by(Entity) %>%
filter(Test = 'Y') %>%
summarise(Avg = mean(head(Value, 3), na.rm = TRUE))
CodePudding user response:
df %>%
group_by(Entity,id = (COUNTER - 1) %/%3 1) %>%
summarise(Running_Avg = mean(Value[Test == 'Y']), .groups = 'drop')
# Groups: Entity [2]
Entity id Running_Avg
<chr> <dbl> <dbl>
1 A 1 7.5
2 A 2 10
3 A 3 5
4 A 4 20
5 B 1 10
6 B 2 20
7 B 3 15
8 B 4 20
CodePudding user response:
I would do this using lag and lead. These let you access values from the previous or the next row.
Start with something like:
step1 = dt %>%
group_by(Entity) %>%
arrange(Date) %>%
mutate(prev_value = lag(Value),
prev_test = lag(Test),
next_value = lead(Value),
next_test = lead(Test))
You can then calculate the mean using each row. Something like:
step2 = step1 %>%
mutate(total = ifelse(Test == 'N', 0, Value)
ifelse(lag_test == 'N', 0, lag_value)
ifelse(lead_test == 'N', 0, lead_value),
obs = ifelse(Test == 'N', 0, 1)
ifelse(lag_test == 'N', 0, 1)
ifelse(lead_test == 'N', 0, 1),
avg = total / obs)
CodePudding user response:
You can do:
df %>%
group_by(Entity) %>%
mutate(id = rep(1:n(), each = 3, length.out = n())) %>%
group_by(Entity, id) %>%
summarize(Avg = mean(Value[Test == "Y"]), .groups = "drop")
which gives:
# A tibble: 8 x 3
Entity id Avg
<chr> <int> <dbl>
1 A 1 7.5
2 A 2 10
3 A 3 5
4 A 4 20
5 B 1 10
6 B 2 20
7 B 3 15
8 B 4 20
So we first create a helper id which groups your data into chunks of 3, and then we simply take the mean of value for all Test == "Y" values.