I am looking for a solution to dynamically select two columns from a dataframe (using ipywidgets or steamlit for example) and create a new dataframe using that selection.
The aim is to allow a user to select two columns from a larger dataset to allow filtering of those two columns to remove NaNs for regression and plotting. I do not want to type every column header out as the dataframe will change for every use. Any help would be of much help!
import ipywidgets as widgets
import pandas as pd
df = pd.DataFrame({'A' : [4,NaN], 'B' : [10,20], 'C' : [100,50], 'D' : [-30,-50]})
x_choice = widgets.Dropdown(
options=list(df.select_dtypes('number').columns)[0:],
description='Number:',
disabled=False,
)
y_choice = widgets.Dropdown(
options=list(df.select_dtypes('number').columns)[1:],
description='Number:',
disabled=False,
)
dfX = pd.DataFrame(x_choice, y_choice)
dfX.dropna()
CodePudding user response:
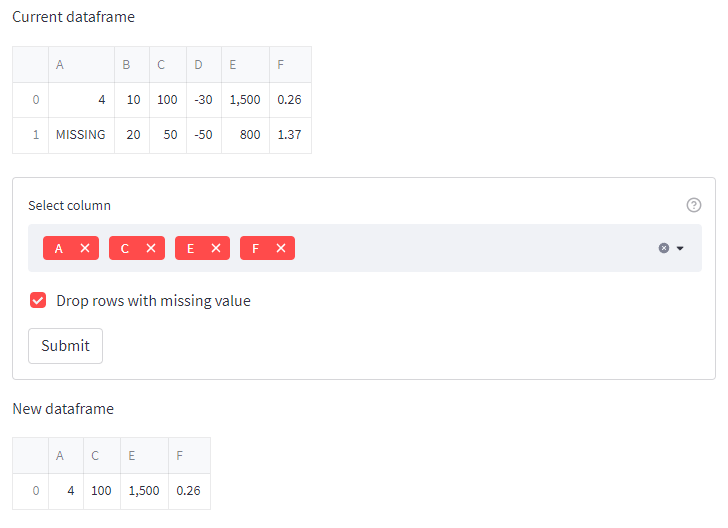
This one is using the streamlit approach. Frame is styled to look it better when displayed using st.dataframe() but you can ignore it.
Code
"""
Creates a new datafame based on selected column from existing dataframe.
"""
import pandas as pd
import streamlit as st
df = pd.DataFrame({'A' : [4,None], 'B' : [10,20],
'C' : [100,50], 'D' : [-30,-50],
'E' : [1500,800], 'F' : [0.258,1.366]})
# Apply styler so that the A column will be displayed with integer value because there is None in it.
df_style = df.style.format(precision=2, na_rep='MISSING', thousands=",", formatter={('A'): "{:.0f}"})
st.write('Current dataframe')
st.dataframe(df_style)
# We use a form to wait for the user to finish selecting columns.
# The user would press the submit button when done.
# This is done to optimize the streamlit application performance.
# As we know streamlit will re-run the code from top to bottom
# whenever the user changes the column selections.
with st.form('form'):
sel_column = st.multiselect('Select column', df.columns,
help='Select a column to form a new dataframe. Press submit when done.')
drop_na = st.checkbox('Drop rows with missing value', value=True)
submitted = st.form_submit_button("Submit")
if submitted:
dfnew = df[sel_column]
if drop_na:
dfnew = dfnew.dropna()
st.write('New dataframe')
dfnew_style = dfnew.style.format(precision=2, na_rep='MISSING', thousands=",", formatter={('A'): "{:.0f}"})
st.dataframe(dfnew_style)
Output
CodePudding user response:
A way to do that is to create a different callback function for each of the dropdowns and create a new dataframe inside each of these functions that only keeps the columns selected by the dropdowns.
See code below:
import ipywidgets as widgets
import pandas as pd
df = pd.DataFrame({'A' : [4,10], 'B' : [10,20], 'C' : [100,50], 'D' : [-30,-50]})
x_choice = widgets.Dropdown(
options=list(df.select_dtypes('number').columns)[0:],
description='Number:',
disabled=False,
)
y_choice = widgets.Dropdown(
options=list(df.select_dtypes('number').columns)[1:],
description='Number:',
disabled=False,
)
def update_dropdown_x(change):
df_new = df[[change.new,y_choice.value]].copy()
print(df_new)
def update_dropdown_y(change):
df_new = df[[x_choice.value,change.new]].copy()
print(df_new)
x_choice.observe(update_dropdown_x,names='value')
y_choice.observe(update_dropdown_y,names='value')
display(x_choice,y_choice)
And below is an example of the variable df_new after selecting columns B and C:
B C
0 10 100
1 20 50
C and D:
C D
0 100 -30
1 50 -50