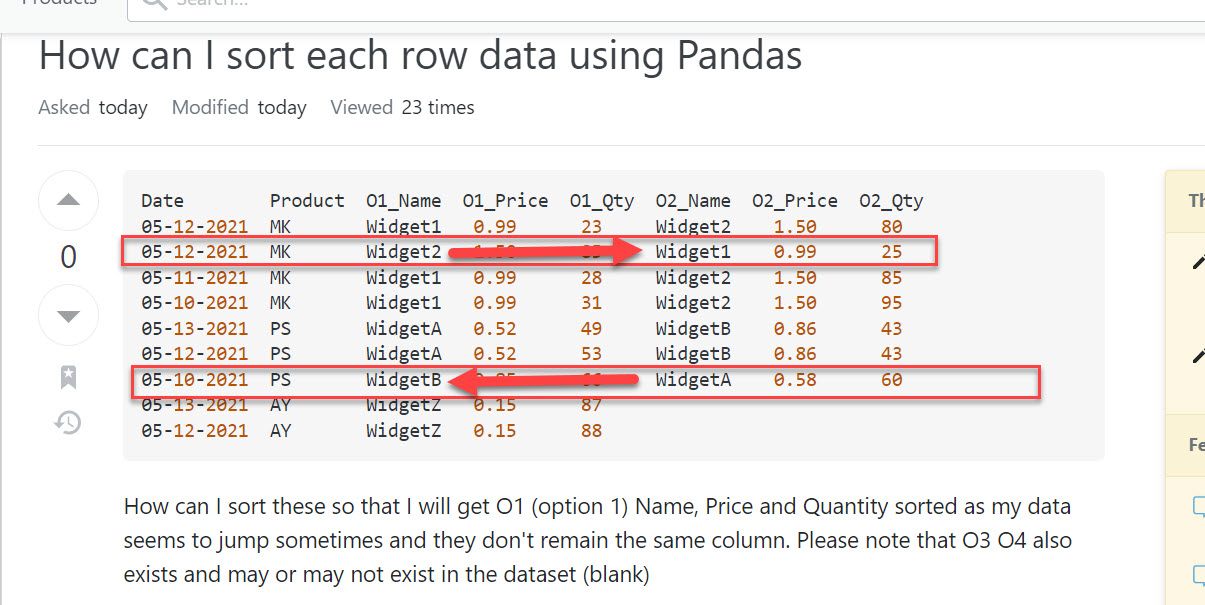
Date Product O1_Name O1_Price O1_Qty O2_Name O2_Price O2_Qty
05-12-2021 MK Widget1 0.99 23 Widget2 1.50 80
05-12-2021 MK Widget2 1.50 85 Widget1 0.99 25
05-11-2021 MK Widget1 0.99 28 Widget2 1.50 85
05-10-2021 MK Widget1 0.99 31 Widget2 1.50 95
05-13-2021 PS WidgetA 0.52 49 WidgetB 0.86 43
05-12-2021 PS WidgetA 0.52 53 WidgetB 0.86 43
05-10-2021 PS WidgetB 0.85 66 WidgetA 0.58 60
05-13-2021 AY WidgetZ 0.15 87
05-12-2021 AY WidgetZ 0.15 88
How can I sort these so that I will get O1 (option 1) Name, Price and Quantity sorted as my data seems to jump sometimes and they don't remain the same column. Please note that O3 O4 also exists and may or may not exist in the dataset (blank)
Forgot to add: Sorting is based on O1_Name O2_Name O3_Name with the Price and Qty following it
RESULT REQUIRED:
Date Product O1_Name O1_Price O1_Qty O2_Name O2_Price O2_Qty
05-12-2021 MK Widget1 0.99 23 Widget2 1.50 80
05-12-2021 MK Widget1 0.99 25 Widget2 1.50 85
05-11-2021 MK Widget1 0.99 28 Widget2 1.50 85
05-10-2021 MK Widget1 0.99 31 Widget2 1.50 95
05-13-2021 PS WidgetA 0.52 49 WidgetB 0.86 43
05-12-2021 PS WidgetA 0.52 53 WidgetB 0.86 43
05-10-2021 PS WidgetA 0.58 60 WidgetB 0.85 66
05-13-2021 AY WidgetZ 0.15 87
05-12-2021 AY WidgetZ 0.15 88
CodePudding user response:
If you want to sort individually, try:
df.sort_values(by=['O1_Name']) # or 'O1_Price'
If you would like to sort by all three together, you can:
df.sort_values(by=['O1_Name', 'O1_Price', 'O1_Qty'])
note that O1_Name will be the first importance for the sorting, and O1_Qty least important.
CodePudding user response:
You can do some fancy reshaping sorting and reshaping again:
df.columns = [('_').join(x) for x in df.columns.str.split('_').str[::-1]]
dfm = pd.wide_to_long(df.reset_index(),
['Name', 'Price', 'Qty'],
i=['index', 'Date', 'Product'],
j='No',
sep='_',
suffix='.*')
dfm = dfm.sort_values(['index', 'Date', 'Product', 'Price'])\
.reset_index('No', drop=True)
dfm = dfm.set_index('O' (dfm.groupby(['index', 'Date', 'Product']).cumcount() 1).astype(str),
append=True)
dfm = dfm.unstack().sort_index(level=1, axis=1)
dfm.columns = dfm.columns.map('_'.join)
df_out = dfm.reset_index()
print(df_out)
Output:
index Date Product Name_O1 Price_O1 Qty_O1 Name_O2 Price_O2 Qty_O2
0 0 05-12-2021 MK Widget1 0.99 23.0 Widget2 1.50 80.0
1 1 05-12-2021 MK Widget1 0.99 25.0 Widget2 1.50 85.0
2 2 05-11-2021 MK Widget1 0.99 28.0 Widget2 1.50 85.0
3 3 05-10-2021 MK Widget1 0.99 31.0 Widget2 1.50 95.0
4 4 05-13-2021 PS WidgetA 0.52 49.0 WidgetB 0.86 43.0
5 5 05-12-2021 PS WidgetA 0.52 53.0 WidgetB 0.86 43.0
6 6 05-10-2021 PS WidgetA 0.58 60.0 WidgetB 0.85 66.0
7 7 05-13-2021 AY WidgetZ 0.15 87.0 None NaN NaN
8 8 05-12-2021 AY WidgetZ 0.15 88.0 None NaN NaN