I am looking to convert data in a textile into a table (data frame) using just methods from Pandas.
Textfile
00100
11110
10110
10111
10101
01111
00111
11100
10000
11001
00010
01010
Table/Dataframe format
0 1 2 3 4
0 0 0 1 0 0
1 1 1 1 1 0
2 1 0 1 1 0
3 1 0 1 1 1
4 1 0 1 0 1
5 0 1 1 1 1
6 0 0 1 1 1
7 1 1 1 0 0
8 1 0 0 0 0
9 1 1 0 0 1
10 0 0 0 1 0
11 0 1 0 1 0
My approach
The only way I could think of doing it was to use some Python code to read the file into a 2D list of characters and then convert that to a data frame:
with open("data.txt") as f:
# Removes newline character and splits binary string into individual character bits
binary = [list(line.strip()) for line in f]
df = pd.DataFrame(binary, dtype="object") # 2D list into pd dataframe
Although this works, I would like to know if this could have been done using Pandas with the read_csv() method
CodePudding user response:
Below code can help. Will also work with txt file
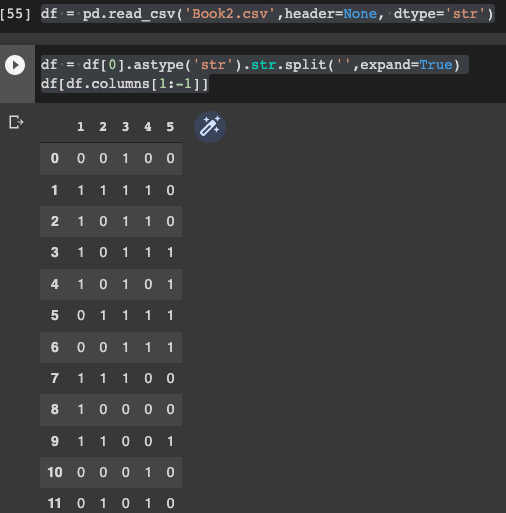
df = pd.read_csv('Book2.csv',header=None, dtype='str') #read file
df = df[0].astype('str').str.split('',expand=True) #split column
df[df.columns[1:-1]] #print df after removing first & last empty column
Output will look like this
CodePudding user response:
This should work in your case:
df = pd.read_fwf('untitled.txt', widths=[1,1,1,1,1])
df.columns = range(df.shape[1])
print(df)
Result:
0 1 2 3 4
0 1 1 1 1 0
1 1 0 1 1 0
2 1 0 1 1 1
3 1 0 1 0 1
4 0 1 1 1 1
5 0 0 1 1 1
6 1 1 1 0 0
7 1 0 0 0 0
8 1 1 0 0 1
9 0 0 0 1 0
10 0 1 0 1 0