I have a streamlit multi-select for different customers, of which I would like only get products which are common to the selected customers.
My pandas dataframe:
customer product version
A iphone 11
A ipad 7
B iphone 11
B ipad 7
B iMac 2012
I would like to get a list of only the products which exists for bot Customer A and B, to be used in another select.
Expected Output:
['iphone', 'ipad']
Any ideas?
CodePudding user response:
I would first get a list of the products associated to A, and the ones associated to B:
product_A = df.loc[df['customer'] == 'A', 'product'].to_list()
product_B = df.loc[df['customer'] == 'B', 'product'].to_list()
Gives:
product_A
['iphone', 'ipad']
product_B
['iphone', 'ipad', 'iMac']
Then get a list of all the possible products (with duplicates removed):
products = df['product'].drop_duplicates().to_list()
['iphone', 'ipad', 'iMac']
You can then use list comprehension to go through each item in products to check if it is both in product_A and product_B:
[i for i in products if (i in product_A) and (i in product_B)]
['iphone', 'ipad']
CodePudding user response:
Here is one approach to address the issue.
Code
import streamlit as st
import pandas as pd
data = {
'customer': ['A', 'A', 'B', 'B', 'B', 'C'],
'product': ['iphone', 'ipad', 'iphone', 'ipad', 'iMac', 'ipad'],
'version': ['11', '7', '11', '7', '2012', '7']
}
df = pd.DataFrame(data)
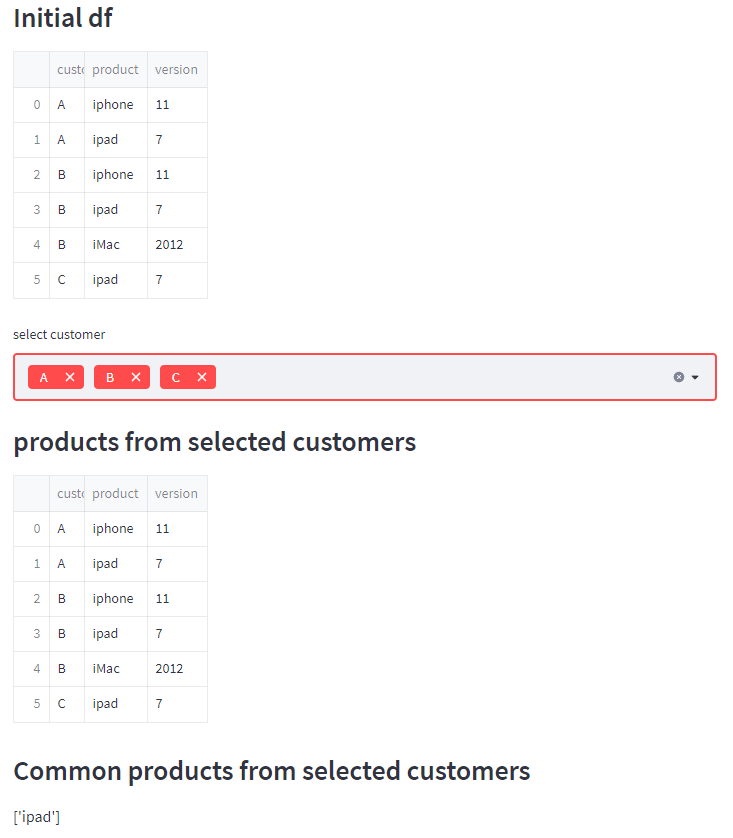
st.write('### Initial df')
st.write(df)
customer_sel = st.multiselect('select customer', df.customer.unique())
if customer_sel:
# Build a dataframe based on the selected customers.
dflist = []
for c in customer_sel:
dfp = df.loc[(df.customer == c)]
dflist.append(dfp)
if dflist:
st.write('### products from selected customers')
dfsel = pd.concat(dflist)
st.write(dfsel)
# Create a dict where product is the key. A product with more than 1
# value will be our common product.
keys = dfsel["product"].unique()
common = {key: 0 for key in keys}
# print(common)
# Group the customer and product.
gb = dfsel.groupby(["customer", "product"])
# The name is a tuple of unique (customer, product) from groupby gb.
for name, _ in gb:
p = name[1] # get the product only
# Count the product from groupby.
common[p] = 1 if common.get(p, None) is not None else 0
# A product is common when it is selected at least once by each customer.
num_customer_sel = len(customer_sel)
common_product = [k for k, v in common.items() if v >= num_customer_sel]
if common_product:
st.write('### Common products from selected customers')
st.write(str(common_product))
Output 1
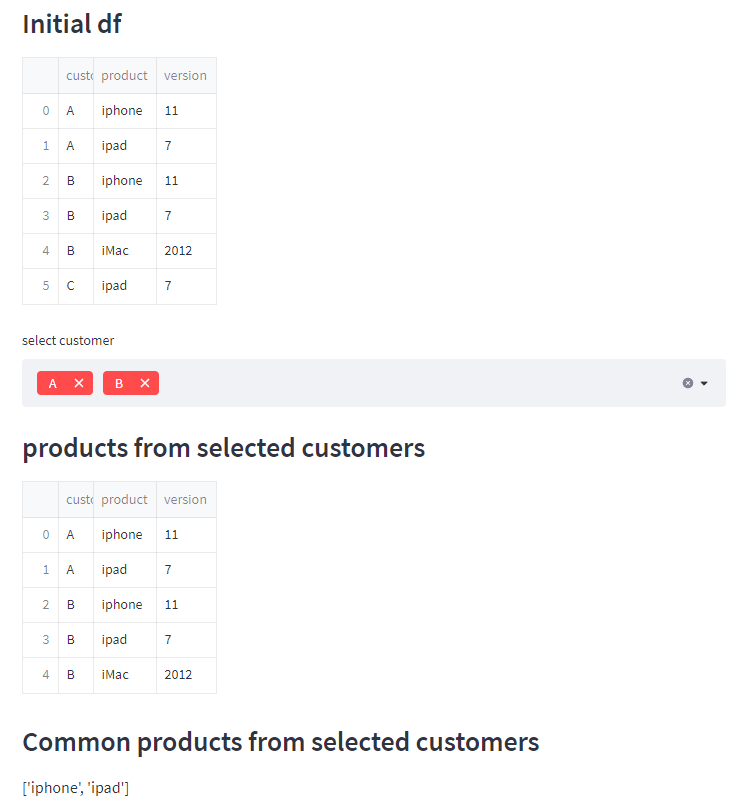
Output 2