After hours of trying I manage to scrape data from a marketplace with selenium. With this code here I took the titles
website = 'https://www.skroutz.gr/c/40/kinhta-thlefwna.html?from=families'
title_list=[]
price_list=[]
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get(website)
#titles = driver.find_elements("class name",'js-sku-link')
titles = driver.find_elements("class name",'js-sku-link')
for title in titles:
print(title.get_attribute('title'))
I took the titles with the class name but I am curious how can I take the price which the structure is like the following screenshot.
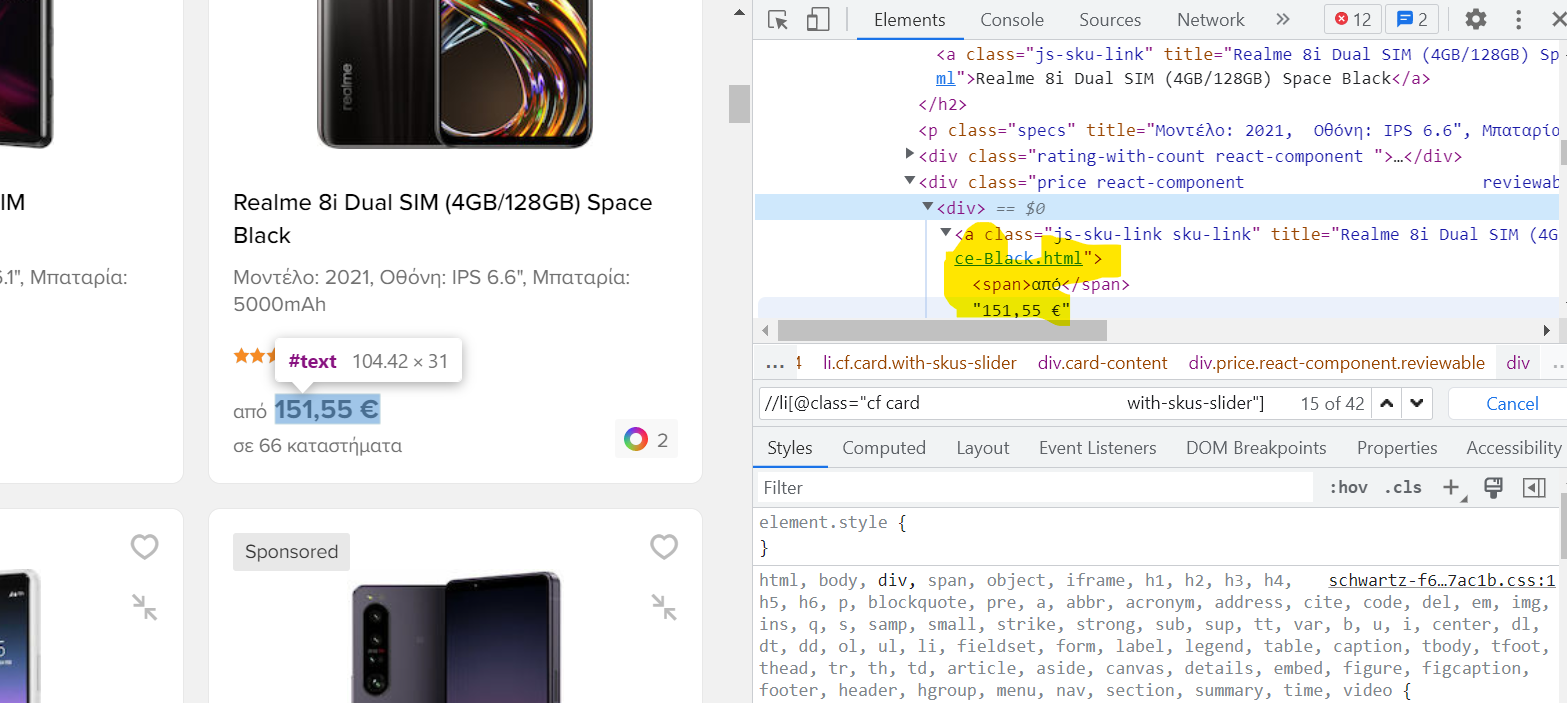
What I should use in this case ?
CodePudding user response:
You can use 'find_elements_by_xpath' to print the prices.
from selenium.webdriver.common.by import By
priceLink = driver.find_elements(by=By.XPATH, value = '//a[@data-e2e-testid="sku-price-link"]')
for price in priceLink:
print(price.text)