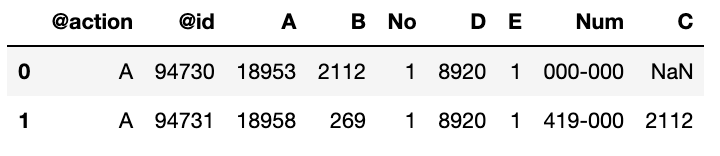
I want to parse through Xml file and convert it to Csv , The columns are dynamic between those Dab tags(As we can see there is an <C> tag in second section not in the first one though. I want to get id attribs and text for the one which has no id. I tried but not able to figure it our as I'm newbie don't know how to deal with dynamic columns. using python pandas NumPy
<Dab action="A" id="94730">
<A id="18953"/>
<B id="2112"/>
<No>1</No>
<D id="8920"/>
<E id="1"/>
<Num>000-000</Num>
</Dab>
<Dab action="A" id="94731">
<A id="18958"/>
<B id="269"/>
<C id="2112"/>
<No>1</No>
<D id="8920"/>
<E id="1"/>
<Num>419-000</Num>
</Dab>
This is result i want to get at the end
CodePudding user response:
With a well-structured xml, try xmltodict:
import xmltodict
xml_dict = xmltodict.parse(xml_data)
df = pd.DataFrame.from_dict(xml_dict)
Example:
xml_data = """
<questionaire>
<question>
<questiontext>Question1</questiontext>
<answer>Your Answer: 99</answer>
</question>
<question>
<questiontext>Question2</questiontext>
<answer>Your Answer: 64</answer>
</question>
<question>
<questiontext>Question3</questiontext>
<answer>Your Answer: 46</answer>
</question>
<question>
<questiontext>Bitte geben</questiontext>
<answer_not_in_others>Your Answer: 544</answer_not_in_others>
<answer>Your Answer: 943</answer>
</question>
</questionaire>
"""
xml_dict = xmltodict.parse(xml_data)
df = pd.DataFrame.from_dict(xml_dict['questionaire']['question'])
df
Output:

Fixing your example (Added a top tag):
xml_data = """
<master>
<Dab action="A" id="94730">
<A id="18953"/>
<B id="2112"/>
<No>1</No>
<D id="8920"/>
<E id="1"/>
<Num>000-000</Num>
</Dab>
<Dab action="A" id="94731">
<A id="18958"/>
<B id="269"/>
<C id="2112"/>
<No>1</No>
<D id="8920"/>
<E id="1"/>
<Num>419-000</Num>
</Dab>
</master>
"""
xml_dict = xmltodict.parse(xml_data)
df = pd.DataFrame.from_dict(xml_dict['master']['Dab'])
Output:

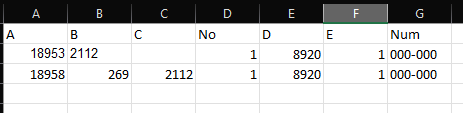
After that you can extract the id values for some columns.
for col in ['A', 'B', 'C', 'D', 'E']:
df[col] = list(map(lambda x: x.get('@id') if type(x) is dict else np.nan, df[col]))
Output: