First of all I have multiple txt files (1000 files) and I will make dataframe from 2 columns. first column is filename of txt file. and 2nd is data if each text files.
I try to write code as below.
import os
import shutil
import pandas as pd
import time
import datetime
import glob
from pathlib import Path
from os import walk
#make df from text
myFiles = glob.glob('C:\\Users\\xxx\\Sub_Folder\\*.txt')
final_df=[]
for item in myFiles:
with open(item, 'rt') as fd:
for first_line in fd.readlines():
splited = first_line.split();
row = []
bbox_temp = []
filename = []
try:
filename.append(''.join([n for n in os.path.basename(item) if n.isdigit()]))
bbox_temp.append(float(splited[1]))
row.append(filename)
row.append(bbox_temp)
final_df.append(row)
except:
print("file is not in YOLO format!")
df = pd.DataFrame(final_df,columns=['filename','bbox'])
for col in ['filename','bbox']:
df[col] = df[col].apply(lambda x: next(iter(x)) if isinstance(x, list) else x)
df['filename'] = df['filename'].replace(
to_replace=['00','01', '02', '03', '04', '05', '06', '07', '08', '09', '10', '11', '12','13','14','15','16','17','18','19','20','21','22','23'],
value=['00:00-00:59', '01:00-01:59', '02:00-02:59', '03:00-03:59','04:00-04:59', '05:00-05:59', '06:00-06:59', '07:00-07:59','08:00-08:59',
'09:00-09:59', '10:00-10:59', '11:00-11:59','12:00-12:59','13:00-13:59','14:00-14:59','15:00-15:59','16:00-16:59','17:00-17:59','18:00-18:59',
'19:00-19:59','20:00-20:59','21:00-21:59','22:00-22:59','23:00-23:59'])
#remove duplicate
df = df.drop_duplicates(subset=['filename','bbox'], keep='first')
#Find max each text file
df = df.groupby(['filename']).agg({'bbox':'max'})
# Export to csv
df.to_csv('C:\\Users\\xxx\\CountingCSV\\total_count.csv', sep='\t')
I got csv file as below. And I checked data space so weird.
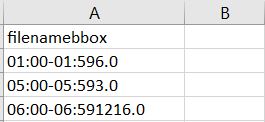

so I want to separate data as below.
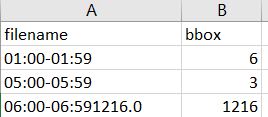
Please supporting me for separate .csv file column
for text file is yolo strong sort label file

I will use only blue highlight data and filename.
CodePudding user response:
IIUC use:
df = df.assign(filename = df['filename'].str[:11], bbox= df['filename'].str[11:])
EDIT: For extract second column use:
import os
myFiles = glob.glob('C:\\Users\\xxx\\Sub_Folder\\*.txt')
dfs= ([pd.read_csv(fp, sep='\s ').iloc[:, [1]]
.assign(f=os.path.basename(fp).split('.')[0])
.set_axis(['bbox','filename'], axis=1)[['filename','bbox']] for fp in myFiles])
df = pd.concat(dfs, ignore_index=True)