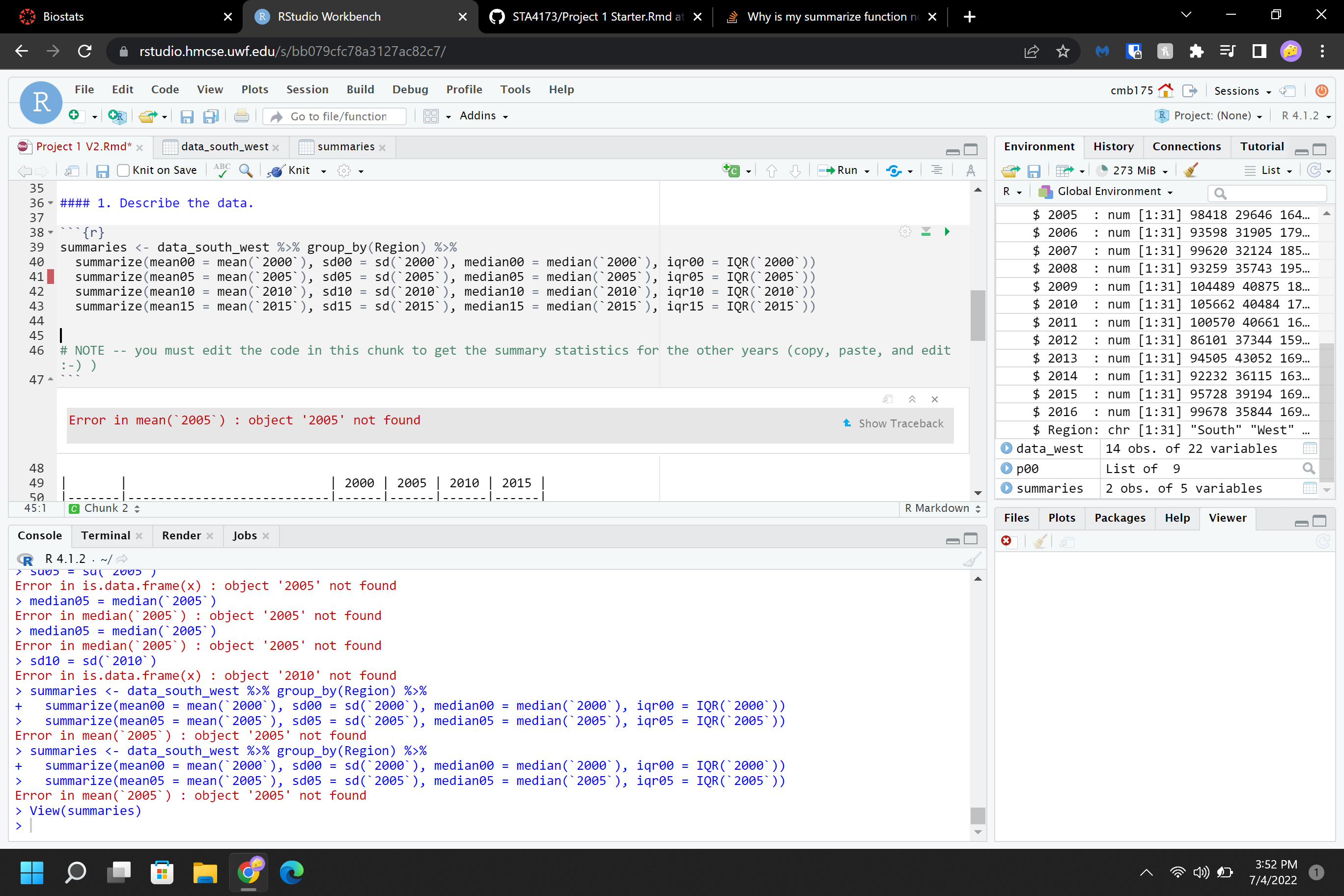
This is my first time using R so I was given a starter code for the project. The summary function that was provided for the year 2000 is:
summaries <- data_south_west %>% group_by(Region) %>%
summarize(mean00 = mean(`2000`), sd00 = sd(`2000`), median00 = median(`2000`), iqr00 = IQR(`2000`))
I copied the function as instructed and edited the function:
summarize(mean05 = mean(`2005`), sd05 = sd(`2005`), median05 = median(`2005`), iqr05 = IQR(`2005`))
Why is the year 2000 findable, but 2005 isn't?
CodePudding user response:
The issue is that you code is syntactically wrong. First, to replicate your issue I use some random example data:
library(dplyr)
# Random example data
set.seed(123)
data_south_west <- data.frame(
Region = sample(c("A", "B"), 100, replace = TRUE),
"2000" = runif(100),
"2005" = runif(100),
check.names = FALSE
)
Next, running your code I get the same error you mentioned.
data_south_west %>%
group_by(Region) %>%
summarize(mean00 = mean(`2000`), sd00 = sd(`2000`), median00 = median(`2000`), iqr00 = IQR(`2000`))
#> # A tibble: 2 × 5
#> Region mean00 sd00 median00 iqr00
#> <chr> <dbl> <dbl> <dbl> <dbl>
#> 1 A 0.492 0.261 0.467 0.427
#> 2 B 0.543 0.268 0.572 0.391
summarize(mean05 = mean(`2005`), sd05 = sd(`2005`), median05 = median(`2005`), iqr05 = IQR(`2005`))
#> Error in mean(`2005`): object '2005' not found
The reason is that to connect multiple summarise or other dplyr verbs you have to make use of the pipe operator %>% to pipe the result from one statement into the next. However, in your case simply piping will not fix the issue because after summarizing the result is a dataframe or tibble which no longer has a column named 2005.
Instead, if you want to summarise multiple columns you have to do so in one summarise call, i.e. do:
data_south_west %>%
group_by(Region) %>%
summarize(mean00 = mean(`2000`), sd00 = sd(`2000`), median00 = median(`2000`), iqr00 = IQR(`2000`),
mean05 = mean(`2005`), sd05 = sd(`2005`), median05 = median(`2005`), iqr05 = IQR(`2005`))
#> # A tibble: 2 × 9
#> Region mean00 sd00 median00 iqr00 mean05 sd05 median05 iqr05
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 A 0.492 0.261 0.467 0.427 0.492 0.287 0.503 0.486
#> 2 B 0.543 0.268 0.572 0.391 0.478 0.307 0.472 0.536
However, a less verbose approach to achieve the same result would be to use dplyr::across which allows to apply the same set of functions to multiple data columns. Here I make use of the .name argument to name the columns after summarizing according to your example code.
data_south_west %>%
group_by(Region) %>%
summarize(across(c(`2000`, `2005`),
.fns = list(mean = mean, sd = sd, median = median, iqr = IQR),
.names = "{.fn}{substr(.col, 3, 4)}"
))
#> # A tibble: 2 × 9
#> Region mean00 sd00 median00 iqr00 mean05 sd05 median05 iqr05
#> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 A 0.492 0.261 0.467 0.427 0.492 0.287 0.503 0.486
#> 2 B 0.543 0.268 0.572 0.391 0.478 0.307 0.472 0.536
CodePudding user response:
Your first command works while the second doesn't, because you didn't feed any data into summarize() in the second command.
The first example may span two lines, but it is one command:
summaries <- data_south_west %>% group_by(Region) %>%
summarize(mean00 = mean(`2000`), sd00 = sd(`2000`), median00 = median(`2000`), iqr00 = IQR(`2000`))
The different parts of the command are connected through the assignment operator <- and through pipes %>%.
Pipes in R
What a pipe does, is take the output from the code on one of its sides, and provide it as the first argument for the code on the other side. In the case of the %>% pipe, it takes the output from the left, and provides it as the first argument to the code on the right.
Try running the following example:
"hello" %>% paste("world") %>% print()
It is essentially the same code as print(paste("hello", "world").
The great benefit of using pipes is that you can use them to chain commands one after another, instead of inside of each other. This makes long commands easier to read, more intuitive to interpret (the computer executes them left to right instead of inside to outside), and easier to edit.
The %>% pipe comes from the magrittr package, and is what you'll see in use the most right now. Base R also introduced a pipe recently: since 4.1 you can use |>.
Back to Question
Explaining the working code
In this code:
summaries <- data_south_west %>% group_by(Region) %>%
summarize(mean00 = mean(`2000`), sd00 = sd(`2000`), median00 = median(`2000`), iqr00 = IQR(`2000`))
the first pipe takes the contents of data_south_west, feeds them into group_by() as its first argument, which then becomes group_by(data_south_west, Region).
The second pipe takes the result from group_by() and feeds it into summarize(), which becomes:
summarize(<the_result_of_group_by>, mean00 = mean(`2000`), sd00 = sd(`2000`), median00 = median(`2000`), iqr00 = IQR(`2000`))
Finally after summarize() is done, the result of that is put into summaries by <-.
Error
The following code:
summarize(mean05 = mean(`2005`), sd05 = sd(`2005`), median05 = median(`2005`), iqr05 = IQR(`2005`))
is different from the working code, as the first argument is lacking. You can either provide it in place, or through a pipe:
summarize(data_south_west, mean05 = mean(`2005`), sd05 = sd(`2005`), median05 = median(`2005`), iqr05 = IQR(`2005`))
data_south_west %>% summarize( mean05 = mean(`2005`), sd05 = sd(`2005`), median05 = median(`2005`), iqr05 = IQR(`2005`))