I have a dataframe and I want to evaluate a formula such like
result = 2*apple - melon - orange and group by testid.
my df is like below
df = pd.DataFrame({'testid':(1,2,1,2,1,2),'Name':('apple','apple','melon','melon','orange','orange'), 'A': (1,2,10,20,5,5), 'B': (1,5,4,2,3,1)})
| testid | Name | A | B |
|---|---|---|---|
| 1 | apple | 1 | 1 |
| 2 | apple | 2 | 5 |
| 1 | melon | 10 | 4 |
| 2 | melon | 20 | 2 |
| 1 | orange | 5 | 3 |
| 2 | orange | 5 | 1 |
and I want my result as for each testid's column A and B, do apple * 2 - melon - orange. and then save into new column result_A and result_B, group by testid
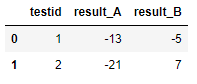
| testid | result_A | result_B |
|---|---|---|
| 1 | -13 | -5 |
| 2 | -21 | 7 |
which function can get this result?
I tried to use df.eval() like
eq = 'df[df.Name==\'apple\',[\'A\',\'B\']] *2 - df[df.Name==\'melon\',[\'A\',\'B\']] - df[df.Name==\'orange\',[\'A\',\'B\']]'
df.eval(eq)
but it tells me
UndefinedVariableError: name 'df' is not defined
i realized i should use pd.eval(engine='python') instead of df.eval() and now the problem is that different subset of df return different index which result them cannot add or minus
df[df.Name=='apple'][['A','B']]*2
this gives me
| A | B | |
|---|---|---|
| 0 | 2 | 2 |
| 1 | 4 | 10 |
however
df[df.Name=='melon'][['A','B']]
this gives me
| A | B | |
|---|---|---|
| 2 | 10 | 4 |
| 3 | 20 | 2 |
so they can't add or minus together because index not match
CodePudding user response:
Try this
(
df
.pivot('testid', 'Name', ['A', 'B'])# reshape df into a wide multiindex df
.stack(0) # remove multiindex
.eval('apple*2-melon-orange') # apply formula (creates a Series)
.unstack() # convert to df
.add_prefix('result_') # add prefix to column names
.reset_index()
)
CodePudding user response:
You can define a method first (assuming there is only one apple, melon, orange for each test id)
def compute(g):
a = g.loc[g['Name']=='apple'].iloc[0]
m = g.loc[g['Name']=='melon'].iloc[0]
o = g.loc[g['Name']=='orange'].iloc[0]
return pd.DataFrame({'A':[a['A']*2 - m['A'] - o['A']],
'B':[a['B']*2 - m['B'] - o['B']]}, index=pd.Index([0]))
Then apply on the group like:
df = df.groupby('testid').apply(compute).reset_index(level=1, drop=True).reset_index()
print(df):
testid A B
0 1 -13 -5
1 2 -21 7