Let's say we have pandas dataframe pd and a dask dataframe dd. When I want to plot pandas one with matplotlib I can easily do it:
fig, ax = plt.subplots()
ax.bar(pd["series1"], pd["series2"])
fig.savefig(path)
However, when I am trying to do the same with dask dataframe I am getting Type Errors such as:
TypeError: Cannot interpret 'string[python]' as a data type
string[python] is just an example, whatever is your dd["series1"] datatype will be inputed here.
So my question is: What is the proper way to use matplotlib with dask, and is this even a good idea to combine the two libraries?
CodePudding user response:
One motivation to use dask instead of pandas is the size of the data. As such, swapping pandas DataFrame with dask DataFrame might not be feasible. Imagine a scatter plot, this might work well with 10K points, but if the dask dataframe is a billion rows, a plain matplotlib scatter is probably a bad idea (datashader is a more appropriate tool).
Some graphical representations are less sensitive to the size of the data, e.g. normalized bar chart should work well, as long as the number of categories does not scale with the data. In this case the easiest solution is to use dask to compute the statistics of interest before plotting them using pandas.
To summarise: I would consider the nature of the chart, figure out the best tool/representation, and if it's something that can/should be done with matplotlib, then I would run computations on dask DataFrame to get the reduced result as a pandas dataframe and proceed with the matplotlib
CodePudding user response:
SultanOrazbayev's is still spot on, here is an answer elaborating on the datashader option (which hvplot call under the hood).
Don't use Matplotlib, use hvPlot!
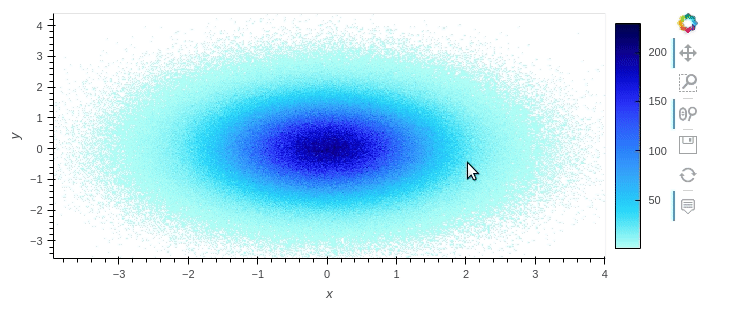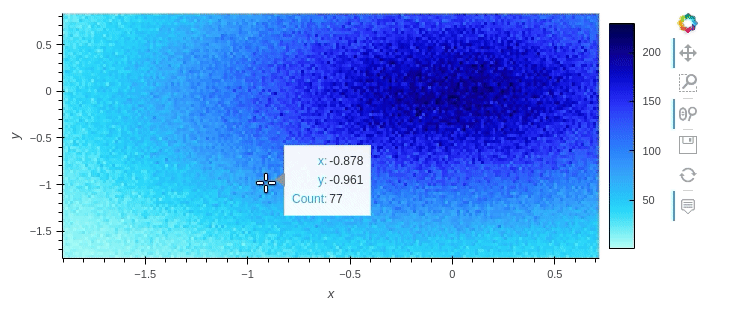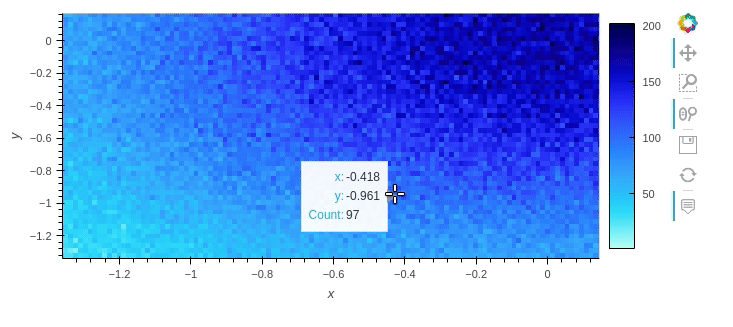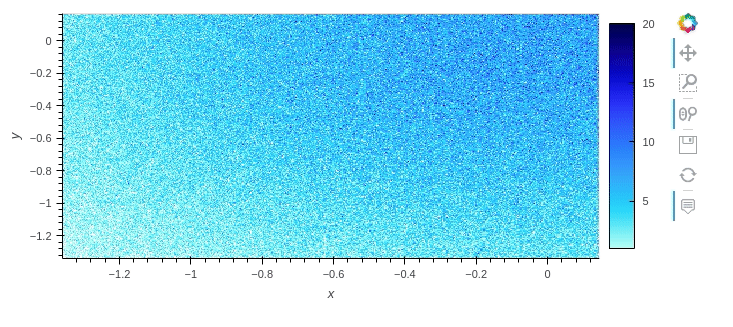
If you wish to plot the data while it's still large, I recommend using hvPlot, as it can natively handle dask dataframes. It also automatically provides interactivity.
Example
import numpy as np
import dask
import hvplot.dask
# Create Dask DataFrame with normally distributed data
df = dask.datasets.timeseries()
df['x'] = df['x'].map_partitions(lambda x: np.random.randn(len(x)))
df['y'] = df['y'].map_partitions(lambda x: np.random.randn(len(x)))
# Plot
df.hvplot.scatter(x='x', y='y', rasterize=True)