I want to make shorter the long quotes in a large txt. My lines:
'Az ital miatt lettem szerelmes, A szerelem miatt pedig adósságba futottam, És bár küzdöttem, küzdöttem és küzdöttem, mégsem tudok szabadulni tőlük. Alexander Brome
'E. T." volt az a film, ami miatt egyáltalán filmet akartam csinálni, és ez volt az első film, ami miatt a filmben történtek helyett az írásra koncentráltam. Adam Green
'Egy szolgának elég, ha egy egyetemen nevelkedik. De az oktatás egy kicsit túl pedáns egy úriembernek. William Congreve
'Elég könnyű kellemesnek lenni, amikor az élet úgy folyik, mint egy dal, de az az ember érdemes, aki akkor is mosolyog, amikor minden balul sül el. Ella Wheeler Wilcox
'Helló, a nevem a Republikánus Párt, és van egy problémám. A költekezés és a nagy kormány rabja vagyok.' Szeretném, ha valamelyikük csak felállna és kimondaná ezt. Glenn Beck
'Háború mindenki ellen, 'Azt hiszem. a forgatókönyv számomra vicces volt, de ez nagyon sötét, sötét humor. Szuper sötét. Michael Pena
The result I need:
'Az ital miatt lettem szerelmes, A szerelem miatt pedig adósságba ... Alexander Brome
'E. T." volt az a film, ami miatt egyáltalán filmet ... Adam Green
'Egy szolgának elég, ha egy egyetemen nevelkedik. De az oktatás ... William Congreve
'Elég könnyű kellemesnek lenni, amikor az élet úgy folyik, mint ... Ella Wheeler Wilcox
'Helló, a nevem a Republikánus Párt, és van egy problémám. ... Glenn Beck
'Háború mindenki ellen, 'Azt hiszem. a forgatókönyv számomra vicces volt, ... Michael Pena
My regex works well for some lines.
Search:
^(.*? .*? .*? .*? .*? .*? .*? .*? .*? .*? .*?).* (.*)
Replace:
$1... $2
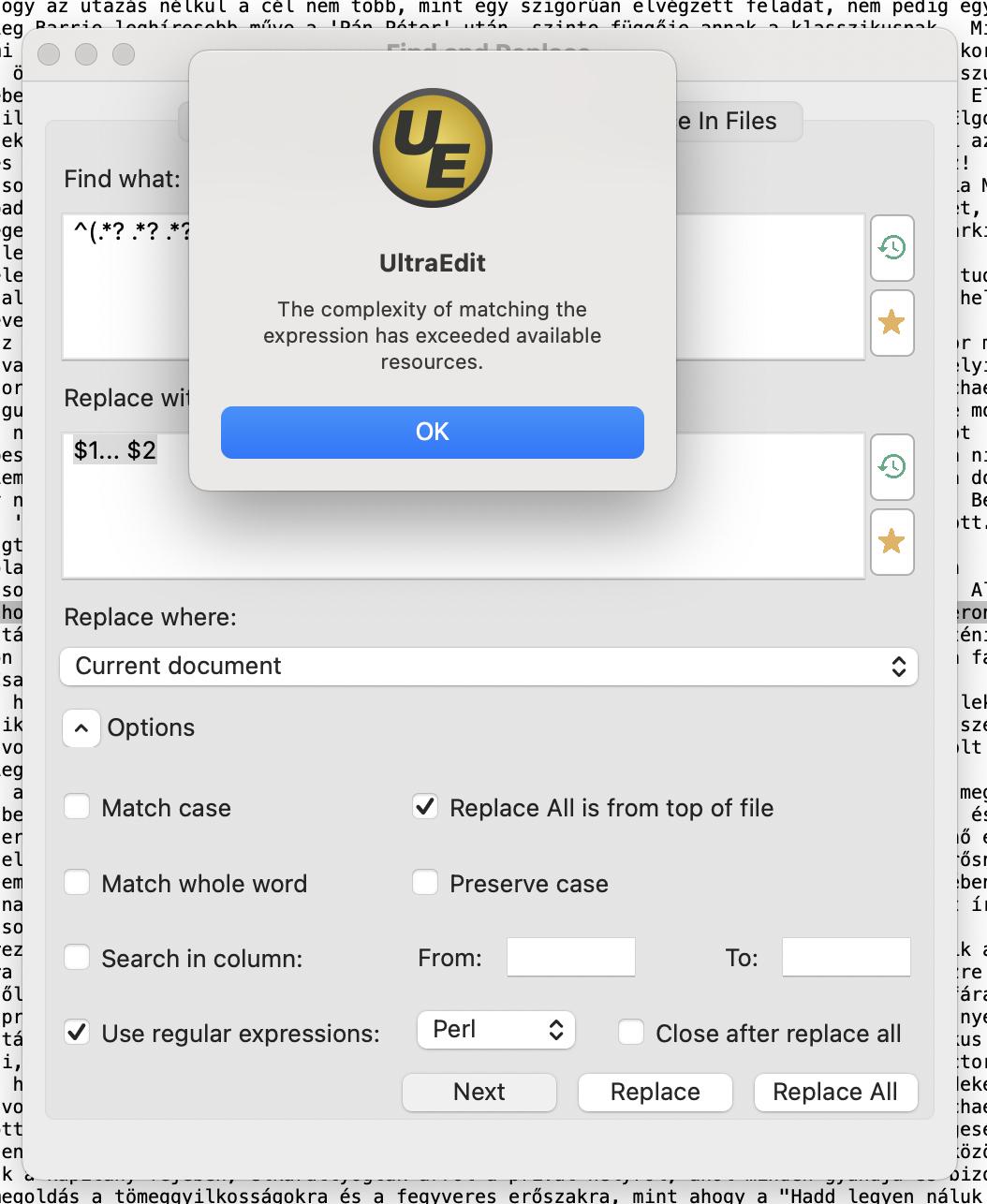
But after some replaces I got an Ultraedit popup error:
"The complexity of matching ... available resources."
I use an M1 Macbook without any problems with other softwares.
Is there any similar, but much simple regex rule to make this cut function?
I want to delete everything after ten words until the tab before the author, and to replace with three dots.
CodePudding user response:
I don't have UlraEdit but assuming each quote is on a single line and there is always an actual tab character before the author, how about:
^(\S (?: \S ){9}).*?\t(. )$
The replacement string is the same.
$1... $2
I will provide further explanation if it works for you or on request.
Note that the regex uses \S to match any non-space character so, for example, a comma will count as a word. If this is a problem then change \S to, for example, [^\s,].
CodePudding user response:
You can use much simpler regex if all you want to capture is first 10 textual tokens in the sentence and want to append it with "..." and want to retain the text after last period. You should use following regex,
^(\s*(?:\S \s ){10}).*\.\s*(.*)
And replace it with,
\1... \2
You don't need to use a non-exhaustive regex as it will have to do a lot of backtracking resulting in poor performance. Just capture ten sequence of some text using \S followed by at least one whitespace using \s and you capture the matched text in group1 and remaining text after last period in group2 and replace it with \1... \2 as you desire. The results after replacement looks exactly as you want.
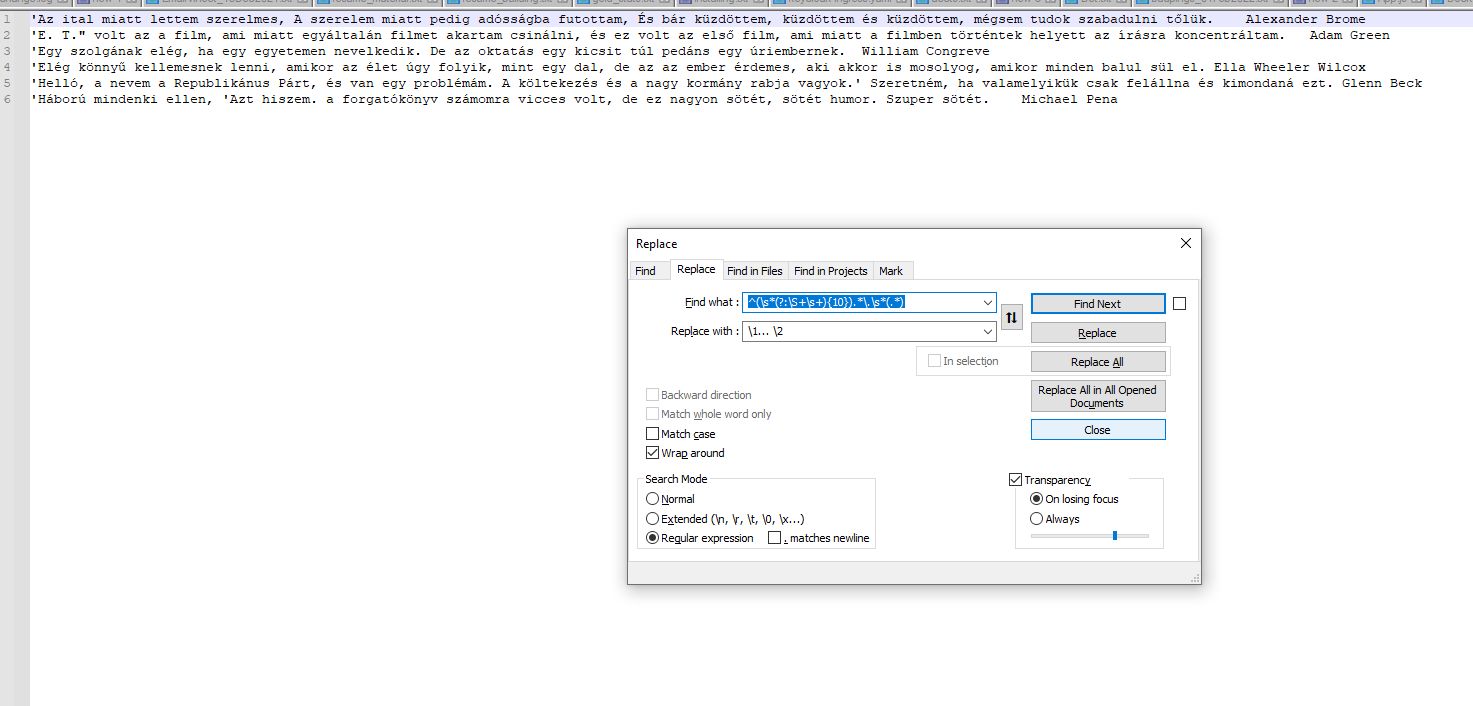
Check the screenshots,
Before:
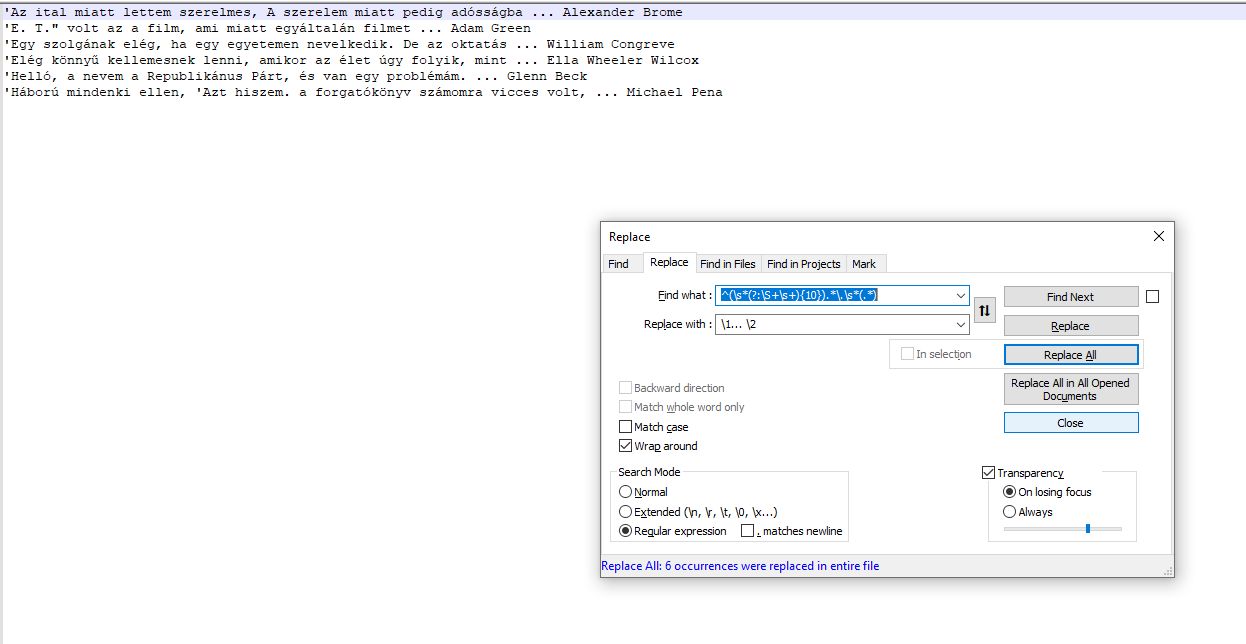
After:
CodePudding user response:
There can be used also the search expression:
^(?:[^\t\n\r ]* ?){1,10}\K.*?(?: {3,} |\t)
The replace expression is ... with space at end.
Explanation of the search expression:
^ ... start each search at beginning of a line.
(?:...^) ... non-marking group on which a multiplier is applied, see below.
[^\t\n\r ]* ? ... find a string not containing a horizontal tab or a line-feed or a carriage return or a normal space zero or more times possessive followed optionally by a space.
The usage of the possessive quantifier is the solution to avoid the complexity error message. It prevents the regular expression engine from going forward and backward in the character stream dozens of times to find the optimal match without finding it ever.
{1,10} ... apply the expression inside the non-marking group at least one but not more than ten times.
\K ... resets the start location of $0 to the current text position: in other words everything to the left of \K is kept back and does not form part of the regular expression match.
.*? ... match zero or more characters except newline characters non-greedy.
(?: {3,} |\t) ... non-marking group to match at least three spaces or a horizontal tab character.
That Perl compatible regular expression replace was tested with UltraEdit for Windows v2022.0.0.102 on the example data on which some additional lines were added by me for additional use cases.
Note: There is not used \s (all whitespaces characters according to Unicode) or \S (all non-whitespace characters according to Unicode) as it would be also possible because of being slower on running the replace than a character class with just the whitespace characters of interest although the execution time difference can be seen only on running the replace on a file with some GB on a modern computer. Further I think it is better to keep two words with a no-break space or a zero-width joiner or an en-space together.
There should be run next one more regular expression replace with (?<! )(?=\.\.\.) as search expression and a single space as replace string to insert a space left to ... if there is no space before the three dots.
There could be used of course also the horizontal ellipses character with code point value U 2026 and no spaces before and after it instead of three dots and the spaces before and after the three dots which would be grammatically better if a Unicode encoding like UTF-8 or UTF-16 is used for the text file.