Simplifying my big problem into this
I have the following datafarme:
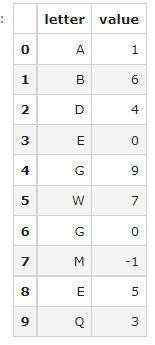
import pandas as pd
df = pd.DataFrame({"letter":['A','B','D','E','G','W','G','M','E','Q'],'value':[1,6,4,0,9,7,0,-1,5,3]})
and a list of items (name and value):
items = [['John',1],['Mike',8],['Jessica',4]]
My goal is to add the letters in the df to the items such that if the value in the df the value in the 'item' is even - the letters should be added to the name.
So what have I done?
for i in items:
name = i[0]
v = i[1]
df['is_even'] = df.apply(lambda x: (x['value'] v)%2==0, axis=1)
letters = list(df[df['is_even']]['letter'].values)
i.append(letters)
and I get the correct result:
['John', 1, ['A', 'G', 'W', 'M', 'E', 'Q']]
['Mike', 8, ['B', 'D', 'E', 'G']]
['Jessica', 4, ['B', 'D', 'E', 'G']]
Problem: note the df has 10 items (N) and the list is 3 items (M) so there are NxM iterations =30. In the real world I have 50,000 rows and 100 items which makes a whopping 500,000 iterations. Too slow.
Any idea how to improve this.
CodePudding user response:
Using group aggregation and a simple loop for in place modification of items.
The solution is O(n):
# aggregate the letters according to odd/even values
s = df.groupby(df['value'].mod(2))['letter'].agg(list)
# value
# 0 [B, D, E, G]
# 1 [A, G, W, M, E, Q]
# Name: letter, dtype: object
# update items in place according to odd/even subitem 1
for l in items:
l.append(s[l[1]%2])
print(items)
output:
[['John', 1, ['A', 'G', 'W', 'M', 'E', 'Q']],
['Mike', 8, ['B', 'D', 'E', 'G']],
['Jessica', 4, ['B', 'D', 'E', 'G']]]