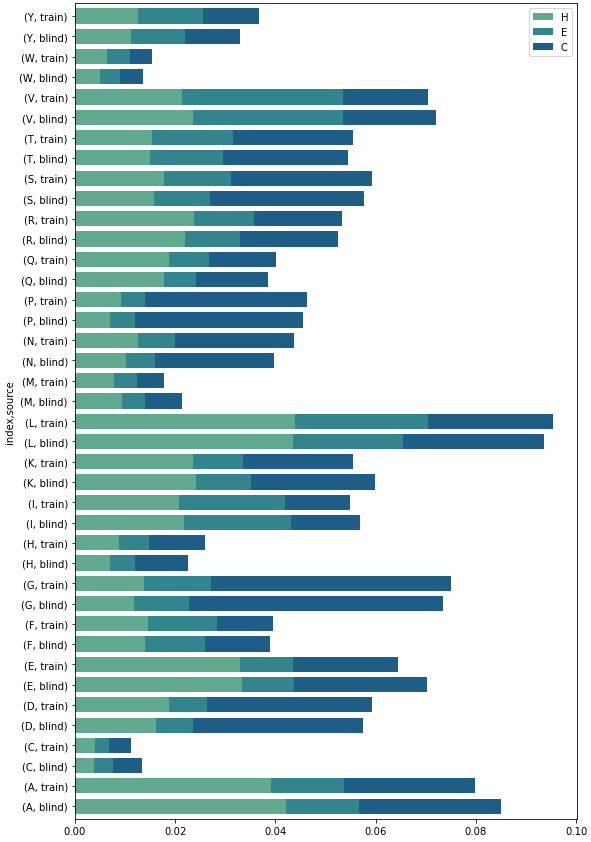
I am creating the plots this way:
fig, ax = plt.subplots(figsize=(8,6))
df = pd.concat((data.assign(source=name) for data, name in zip([train_ss_freq_df, train_ss_freq_df], ['train', 'blind'])))
df[df['source']=='train'].plot(kind='bar', stacked=True, color=sns.color_palette("crest", 3),ax=ax)
df[df['source']=='blind'].plot(kind='bar', stacked=True, color=sns.color_palette("crest", 3),ax=ax)
the datasets are these:
,H,E,C
A,0.039065342828923426,0.014685241981597963,0.026069553464677445
R,0.023860269272755627,0.011930134636377814,0.017492332484275095
N,0.012605915683318605,0.007381608358891719,0.02365233664292769
D,0.018817902999428187,0.007589540988719654,0.03285335551281385
C,0.004028694702916255,0.002729115766491657,0.004470551541300619
Q,0.01886988615688517,0.007849456776004574,0.013437646202630348
E,0.032983313406456306,0.010578572542496232,0.020975204033893018
G,0.013827519883557727,0.013437646202630348,0.04777252170296824
H,0.008733170452773302,0.006004054686281644,0.011150387274523055
I,0.020793262982793576,0.021209128242449447,0.012969797785517493
L,0.04384779331496595,0.02666735977543276,0.024899932421895307
K,0.02352237874928523,0.010084732546654884,0.021832926131933255
M,0.007797473618547591,0.004678484171128554,0.005354265218069345
F,0.01465925040286947,0.013749545147372252,0.011150387274523055
P,0.009201018869886156,0.0047304673285855385,0.03246348183188647
S,0.017856214586473983,0.013229713572802412,0.028278837656599262
T,0.015387014607267246,0.01614077039039351,0.023990227166398086
W,0.006419919945937516,0.004600509434943078,0.004418568383843634
Y,0.01268389041950408,0.012943806206789,0.011202370431980038
V,0.02139106929354889,0.032151582887144564,0.016842543016062795
,H,E,C
A,0.04221830985915493,0.014446680080482898,0.02841549295774648
R,0.02193158953722334,0.011006036217303823,0.019577464788732395
N,0.010206237424547284,0.005719315895372234,0.023712273641851106
D,0.016267605633802817,0.007223340040241449,0.03400905432595573
C,0.0037927565392354124,0.0037374245472837023,0.005960764587525151
Q,0.017751509054325956,0.0064285714285714285,0.014305835010060362
E,0.03344567404426559,0.010326961770623743,0.026398390342052314
G,0.01176056338028169,0.011066398390342052,0.05057344064386318
H,0.00698692152917505,0.005060362173038229,0.01062374245472837
I,0.02187122736418511,0.02117706237424547,0.01375251509054326
L,0.043470824949698186,0.022062374245472836,0.028118712273641853
K,0.024170020120724348,0.011036217303822938,0.024622736418511065
M,0.009476861167002013,0.004592555331991952,0.007339034205231389
F,0.01391851106639839,0.011956740442655935,0.013083501006036218
P,0.007027162977867203,0.004964788732394366,0.033591549295774646
S,0.015774647887323943,0.01119718309859155,0.030653923541247484
T,0.015020120724346076,0.014507042253521127,0.024899396378269618
W,0.004964788732394366,0.003958752515090543,0.004678068410462776
Y,0.011156941649899397,0.010789738430583501,0.011091549295774649
V,0.023586519114688127,0.02992957746478873,0.018606639839034204
The problem is that they're overlapping. How can I make them side by side but still in the same figure? I concatenated them in the hope of finding a way to separate them by "source", but I haven't found the right argument to do so.
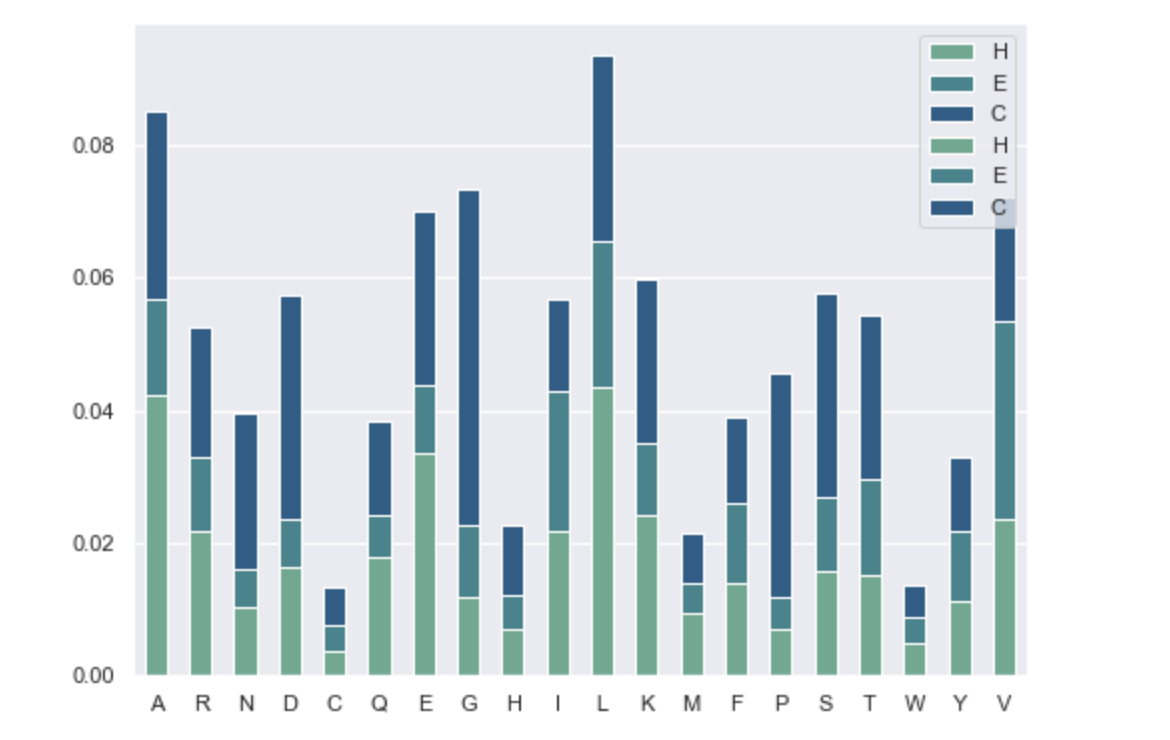
CodePudding user response:
- If the plot must be grouped and clustered, there is this
DataFrame Views
df.head()H E C source A 0.039065 0.014685 0.026070 train R 0.023860 0.011930 0.017492 train N 0.012606 0.007382 0.023652 train D 0.018818 0.007590 0.032853 train C 0.004029 0.002729 0.004471 traindfp.head(6)H E C index source A blind 0.042218 0.014447 0.028415 train 0.039065 0.014685 0.026070 C blind 0.003793 0.003737 0.005961 train 0.004029 0.002729 0.004471 D blind 0.016268 0.007223 0.034009 train 0.018818 0.007590 0.032853