How to make this work?
df['sum_greater_then'] = df.groupby(['scan_number', 'raw_file]).sort_values('rank', ascending=False)['intensity'].cumsum()
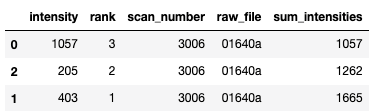
I need to normalize the data. For this I first need to add intensities up based on their rank in the spectra. One spectra is when 'scan_number' and 'raw_file' don't change.
| intensity | rank | scan_number | raw_file |
|---|---|---|---|
| 1,057 | 3 | 3006 | 01640a_BA5 |
| 4,03 | 1 | 3006 | 01640a_BA5 |
| 2,05 | 2 | 3006 | 01640a_BA5 |
These are the calculations, which I need to do:
Rank 1: (4,03 2,05 1,057) / total = 7,137/7,137 = 1
Rank 2: (2,05 1,057) / total = 0,435
Rank 3: 1,057 / total = 0,148
There are other columns in the dataframe, I don't need them for this specific calculation though.
I already ranked each intensity, calculated the total and created a column each for those values. I just need to add up the right intensities to divide them by total and get the normalized value in the end.
This doesn't work as well
df['sum_greater_then'] = df.groupby(['scan_number', 'raw_file]).apply(lambda x: x.sort_values('rank', ascending=False)['intensity'].cumsum())
CodePudding user response:
This is a little clunky, but I believe achieves what you want.