- Database: PostgresSQL PostgreSQL 12.11 (Ubuntu 12.11-0ubuntu0.20.04.1) on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0, 64-bit
- RAM : 8 GB
- Processor : i7 4510U (dual core 2 Ghz)
I would to like to optimized below query
select a.gender from "employees" as a
where lower( gender ) LIKE 'f%' group by gender
limit 20
Total number of records in table : 2,088,290 rows
Index
CREATE INDEX ix_employees_gender_lower ON public.employees USING btree (lower((gender)::text) varchar_pattern_ops)
query execution plan
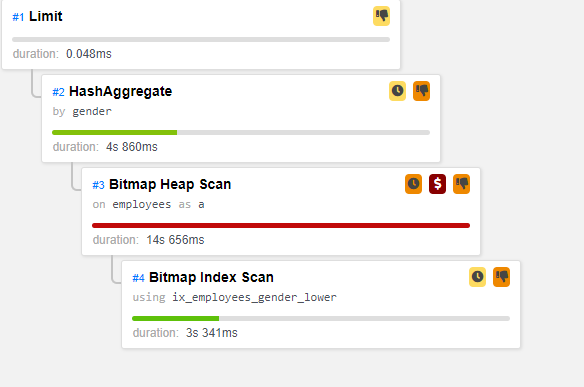
Please use gdrive link to download and restore the sql to database for above query SQL TABLE with data
I tried to index but unavail also i am not able to understand explain analyze so any pointers on the same as well
CodePudding user response:
so apparently
refactoring base query to below
select gender from (
select a.gender from "employees" as a
where lower(a.gender::text) LIKE 'f%'
limit 40) b
group by b.gender
brought the execution time from 5 seconds to 16 ms
CodePudding user response:
Even the bad plan is far better for me than it appears to be for you (4s with completely cold cache, 0.4s upon repeat execution), and my hardware is far from excellent.
If the time is going to random page reads, you could greatly reduce that by creating an index suited for index-only-scans and making sure the table is well vacuum.
CREATE INDEX ix_employees_gender_lower2 ON public.employees USING btree (lower((gender)::text) varchar_pattern_ops, gender)
That reduces the timing to 0.3s, regardless of cache warmth.
But I don't see the point of running this query even once, much less often enough to care if it takes 22s.