I am trying to implement this paper 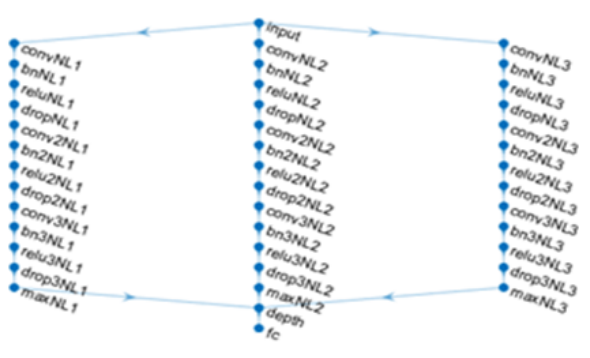
This text is from the Paper itself that describes the layers;
The CNN architecture in Figure 5 is shown in a top-down manner starting from the start (top) to the finish (bottom) node. ‘‘NL’’ stands for N-gram Length. The breakdown is:
- An input layer of size 1 × 100 × N where N is the number of instances from the dataset. Vectors of embedded-words are used as the initial input.
- Then the layers between the input and the concatenation is introduced:
- One convolutional layer with 200 neurons to receive and filter size 1 × 100 × N where N is the number of instances from the dataset. The stride is [1 1].
- Two convolutional layer with 200 neurons to receive and filter size 1 × 100 × 200. The stride is [1 1].
- Three batch normalization with 200 channels.
- Three ReLU activation layers.
- Three dropout layers with 20 percent dropout.
- A max pooling layer with stride [1 1].
- A depth concatenation layer to concatenate all the last max pooling layers.
- A fully connected layer with ten neurons.
The code that I have tried so far is here.
model1 = Input((train_vector1.shape[1:]))
#1_1
model1 = Conv1D(200, filters=train_vector1.shape[0], kernel_size=(1, 100), strides = 1, activation = "relu")(model1)
model1 = BatchNormalization(200)(model1)
model1 = Dropout(0.2)(model1)
#1_2
model1 = Conv1D(200, filters = 200, kernel_size=(1, 100), stride = 1, activation = "relu")(model1)
model1 = BatchNormalization(200)(model1)
model1 = Dropout(0.2)(model1)
#1_3
model1 = Conv1D(200, filters = 200, kernel_size=(1, 100), stride = 1, activation = "relu")(model1)
model1 = BatchNormalization(200)(model1)
model1 = Dropout(0.2)(model1)
model1 = MaxPooling1D(strides=1)(model1)
model1 = Flatten()(model1)
## Second Part
model2 = Input((train_vector1.shape[1:]))
#2_1
model2 = Conv1D(200, filters=train_vector1.shape[0], kernel_size=(1, 100), strides = 1, activation = "relu")(model2)
model2 = BatchNormalization(200)(model2)
model2 = Dropout(0.2)(model2)
#2_2
model2 = Conv1D(200, filters = 200, kernel_size=(1, 100), stride = 1, activation = "relu")(model2)
model2 = BatchNormalization(200)(model2)
model2 = Dropout(0.2)(model2)
#2_3
model2 = Conv1D(200, filters = 200, kernel_size=(1, 100), stride = 1, activation = "relu")(model2)
model2 = BatchNormalization(200)(model2)
model2 = Dropout(0.2)(model2)
model2 = MaxPooling1D(strides=1)(model2)
model2 = Flatten()(model2)
## Third Part
model3 = Input((train_vector1.shape[1:]))
#3_1
model3 = Conv1D(200, filters=train_vector1.shape[0], kernel_size=(1, 100), strides = 1, activation = "relu")(model3)
model3 = BatchNormalization(200)(model3)
model3 = Dropout(0.2)(model3)
#3_2
model3 = Conv1D(200, filters = 200, kernel_size=(1, 100), stride = 1, activation = "relu")(model3)
model3 = BatchNormalization(200)(model3)
model3 = Dropout(0.2)(model3)
#3_3
model3 = Conv1D(200, filters = 200, kernel_size=(1, 100), stride = 1, activation = "relu")(model3)
model3 = BatchNormalization(200)(model3)
model3 = Dropout(0.2)(model3)
model3 = MaxPooling1D(strides=1)(model3)
model3 = Flatten()(model3)
concat_model = Concatenate()([model1, model2, model3])
output = Dense(10, activation='sigmoid')
I just want to know if my implementation is correct here, or am I misinterpreting something? Am I understanding what the author is trying to do here?
CodePudding user response:
From that image I think that the input could be shared among the other layers. In that case you would have:
input = Input((train_vector1.shape[1:]))
model1 = Conv1D(...)(input)
# ...
model1 = Flatten()(model1)
model2 = Conv1D(...)(input)
# ...
model2 = Flatten()(model2)
model3 = Conv1D(...)(input)
# ...
model3 = Flatten()(model3)
concat_model = Concatenate()([model1, model2, model3])
output = Dense(10, activation='sigmoid')
Also most probably the convolutions are not 1D but 2D. You can get confirmation of it from the fact that it says:
The stride is [1 1]
Se we are in two dimensions. Same for MaxPooling.
Also you said:
when I run this code, it say too many arguments for "filters". Am I doing anything wrong here?
Let's take:
model1 = Conv1D(200, filters=train_vector1.shape[0], kernel_size=(1, 100), strides = 1, activation = "relu")(model1)
The Conv1D function accepts this arguments (full documentation):
tf.keras.layers.Conv1D(
filters,
kernel_size,
strides=1,
...
)
It says too many arguments because you are trying to write the number of neurons of the Convolutional layer, but there is simply no argument for that, so you don't have to. The number of neurons depends on the other parameters you set.
Same thing also for BatchNormalization. From the docs:
tf.keras.layers.BatchNormalization(
axis=-1,
momentum=0.99,
...
)
There is no "number of neurons" argument.