Straight to the "issue".
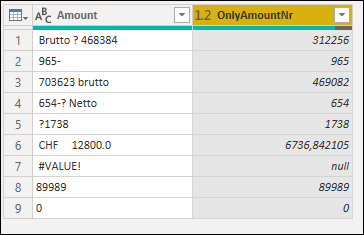
I got one "simple" task to try to solve in Power BI > Power Query, where I got one mixed column supposed to be an Amount column, with lot of different number/text/special chars combinations, which have to be firstly converted into number format and then conditionally calculated if there is "brutto (no case sensitive) in general", then divide that value with 1.5 and if there is CHF value divide that value with 1.9. The rest of data, like errors, #values or even nulls can be removed. Expected column is shown as OnlyAmountNr and in my Query steps.
This is short example of my data:
| Amount | OnlyAmountNr |
|-----------------|--------------|
| Brutto ? 468384 | 468384 |
| 965- | 965 |
| 703623 brutto | 703623 |
| 654-? Netto | 654 |
| ?1738 | 1738 |
| CHF 12800.0 | 12800 |
| #VALUE! | - |
| 89989 | 89989 |
| 0 | 0 |
What I used, at least to my knowledge are these steps,which might be too long for this kind of task:
let
Quelle = Sql.Databases("ukTest123.database.windows.net"),
CSD_DE_RawData = Quelle{[Name="CSD_DE_RawData"]}[Data],
money_ASD_Applications =
CSD_DE_RawData{[Schema="money",Item="ASD_Applications"]}[Data],
EXTRACT_SPECIAL_CHARS = Table.AddColumn(money_ASD_Applications, "Custom1", each Text.Select([Amount],{"A".."z","0".."9"})),
EXTRACT_NUMBERS = Table.AddColumn(EXTRACT_SPECIAL_CHARS, "Custom2", each Text.Select([Custom1],{"a".."z","A".."Z"})),
EXTRACT_T_F = Table.AddColumn(EXTRACT_NUMBERS, "Boolean", each if Text.Contains([Custom1], "brutto") then true else if Text.Contains([Custom1], "Brutto") then true else false),
EXTRACT_TEXT = Table.AddColumn(EXTRACT_T_F, "OnlyAmountNr", each Text.Remove([Custom1],Text.ToList(Text.Remove([Custom1],{"0".."9"})))),
#"Changed Type" = Table.TransformColumnTypes(EXTRACT_TEXT,{{"OnlyAmountNr", type number}}),
#"CALCULATION_MwSt." = Table.AddColumn(#"Changed Type", "MwSt._CH_DE", each if [OnlyAmountNr]> 1 and [Boolean]= true then ([OnlyAmountNr]/1.199) else if [OnlyAmountNr]>1 and [Custom2]="CHF" then ([OnlyAmountNr]/1.077) else null)
in
#"CALCULATION_MwSt."
CodePudding user response:
I used a custom function implementing Regular Expressions to extract the number. Then added a custom column to implement the logic.
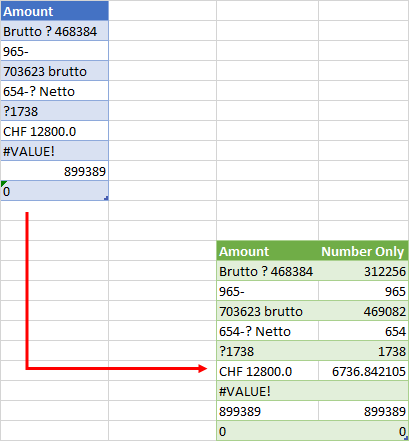
I used the logic in your question, and not the logic in your code. In your code you have different divisors. Also, I was not sure about handling numbers where Amount did not contain brutto (case insensitive) or CHF, so, as per your question statement, I set them to null, but that is easily remedied if that is not what you really intend (just change else null to else n in the custom column formula)
Custom Function
Rename fnRegexExtract
//Rename fnRegexExtract
let fx=(text,regex)=>
Web.Page(
"<script>
var x='"&text&"';
var y=new RegExp('"®ex&"');
var b=x.match(y);
document.write(b);
</script>")[Data]{0}[Children]{0}[Children]{1}[Text]{0}
in
fx
Main Code
let
//change next line to reflect actual data source
Source = Excel.CurrentWorkbook(){[Name="Table7"]}[Content],
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Amount", type text}}),
#"Invoked Custom Function" = Table.AddColumn(#"Changed Type", "Number Only", each let
n =Number.From(fnRegexExtract([Amount], "\\d ")),
result =
if Text.Contains([Amount],"brutto",Comparer.OrdinalIgnoreCase) then n/1.5
else if Text.Contains([Amount],"CHF") then n/1.9
else null
in result, type number)
in
#"Invoked Custom Function"
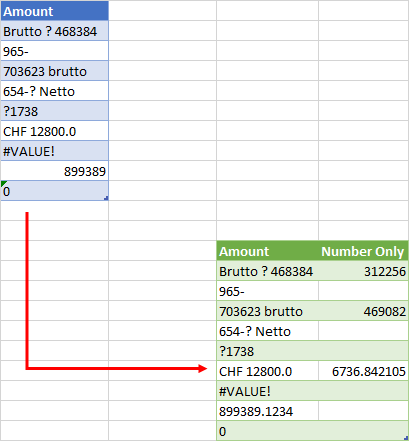
Or, after changing else null to else n
CodePudding user response:
Try this custom column formula to extract the numbers only:
=Number.FromText(
Text.Combine(
List.RemoveNulls(
List.Transform(
Text.ToList(Text.From([Amount])),
each if Value.Is(Value.FromText(_), type number) then _ else null
)
)
)
)
CodePudding user response:
Alternatively use scripting, for example Python or R. When you start a new PowerBI project choose to get data from either of the above options.
Python
- Extract the numbers with potential decimals to a new column using regular expressions. In this case
(\d (?:\.\d )?); - Use 'df.loc' to test another regular expression against all rows in the new column. If it contains
(?i)\bbrutto\bthen devide by 1.5; - Replicate step above but instead look for
(?i)\bchf\band devide by 1.9.
Note: Because I read the dataframe from Excel I also had to install the OpenPyxl package. You can install all these pip packages through any Shell, but I used cmd prompt. 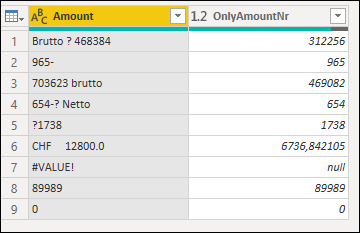
- Extract the numbers with potential decimals using regular expressions. In this case
(?i)\\d (?:\\.\\d )?; - Use 'grepl' for pattern matching with nested 'ifelse' construct to test against
(?i)\\bbrutto\\band devide by 1.5 or test for(?i)\\bchf\\band devide by 1.9.
*Note: I used an Excel-file as my df-source again and thus had to download a package called 'readxl' first. This is easy through R itself. Open R > Packages > Install > Choose a CRAN > readxl. The same route can be used to install 'stringr'.
CodePudding user response:
Its hard to tell what else you are doing in your code, but when you are at the point when you want to extract the number:
#"Added Custom" = Table.AddColumn(#"YourPriorStepNameHere", "OnlyAmountNr", each Text.Select([Amount],{"0".."9","."}))
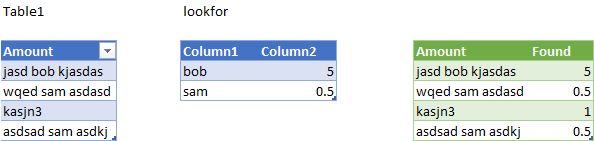
you could additionally create table lookfor as in image below then use this code to pick up the multiplication factor for Amount column when matching text is found
Findmatch = Table.AddColumn(#"PriorStepNameHere", "Found", (x) => try Table.SelectRows(lookfor, each Text.Contains(x[Amount],[Column1], Comparer.OrdinalIgnoreCase))[Column2]{0} otherwise 1)