I'm working on a "word generator" But I have a problem. Sometimes it creates unwanted words. I would like to remove them but not to heavy the loop.
I have to do like the example in the code with the whole alphabet. There would be nothing wrong with it that much, but there are a few other problems that I would have dealt with if only I knew how to cut it short.
# alph = "abcdefghijklmnopqrstuvwyzxą"
my_var = ["abc", "aabc", "cbd", "ccbd", "qwe", "qqwe"]
my_var2 = []
def removeDup():
for x in my_var:
if x.find("aa") == -1 and x.find("cc") == -1 and x.find("qq") == -1:
my_var2.append(x)
print(my_var2)
removeDup()
My idea is dynamic variables, but I can't make one loop in the other without creating chaos
I tried something like the one in the picture, but I can only take out words with repeated letters
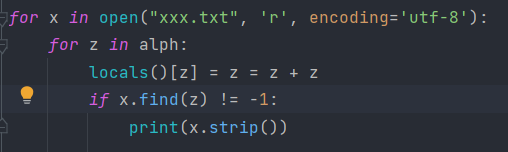
CodePudding user response:
There's no need for dynamic variables. Just make a list of all the duplicate characters.
dups = [z*2 for z in alph]
for x in open('xxx.txt', encoding='utf-8'):
if not any(dup in x for dup in dups):
print(x.strip())