Trying to match string that starts with #1-9 note: # is followed by a number from 1 to 9
and ends with #1-9 (or not).
Full string : "#1Lorem Ipsum is simply dummy text#2printing and typesetting industry"
Idea:
is to replace #1Lorem Ipsum is simply dummy text with <span >Lorem Ipsum is simply dummy text</span>
and #2printing and typesetting industry with <span >printing and typesetting industry</span>
so to replace #1-9 with <span > and append the ending tag </span> at the end of each.
but:
let's say if the string has only one string starting with #1-9 like that :
"#1Lorem Ipsum is simply dummy text" how could be putting </span> at the end to close the <span> tag.
i'm guessing maybe using the last " at the end of words to prepend the closing </span> tag before it, since no more #1-9 to stop before it, but without losing or replacing the last " of the string.
so it becomes: "<span >Lorem Ipsum is simply dummy text</span>"
Regex i've tried : (#[0-9])(.*?)(#|") but this is only matching the first part #1 of the string and ignoring the #2 part (see full string).
I will be using php to match and replace maybe using preg_replace just need to find a way to the regex part first.
How can i achieve this?
CodePudding user response:
What you are looking for is a 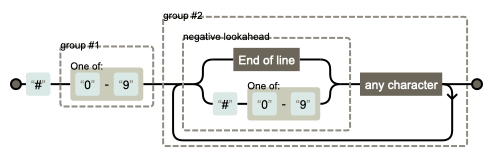
Which was generated using regexper.com
CodePudding user response:
<?php
function convert($str) {
static $numberNamesMap = [
1 => 'one',
2 => 'two',
3 => 'three',
4 => 'four',
5 => 'five',
6 => 'six',
7 => 'seven',
8 => 'eight',
9 => 'nine',
];
return preg_replace_callback(
'~#([1-9])(((?!#[1-9]).)*)~',
function($matches) use ($numberNamesMap) {
$class = $numberNamesMap[$matches[1]];
$htmlText = htmlentities($matches[2]);
return "<span class=\"$class\">$htmlText</span>";
},
$str
);
}
References
- How to negate specific word in regex?
- https://www.php.net/manual/en/function.preg-replace-callback.php
Examples
echo convert('#1Lorem Ipsum is simply dummy text');
outputs:
<span >Lorem Ipsum is simply dummy text</span>
echo convert('#1Lorem Ipsum is simply dummy text#2printing and typesetting industry');
outputs:
<span >Lorem Ipsum is simply dummy text</span><span >printing and typesetting industry</span>
echo convert('#1Lorem Ipsum is simply dummy text#0printing and typesetting industry');
outputs:
<span >Lorem Ipsum is simply dummy text#0printing and typesetting industry</span>
CodePudding user response:
preg_replace_callback() is the right tool for this job. To avoid needing to manually declare a number mapping array, you can use the NumberFormatter class. Using sprintf() in the callback body will help to separate data from the html and make maintenance easier.
Code: (Demo)
$string = '#1Lorem Ipsum is simply dummy text#2printing and typesetting industry#0nothing#35That\'s a big one!';
echo preg_replace_callback(
'/#(\d )((?:(?!#\d).) )/',
fn($m) => sprintf(
'<span >%s</span>',
(new NumberFormatter("en", NumberFormatter::SPELLOUT))->format($m[1]),
htmlentities($m[2])
),
$string
);
Output:
<span >Lorem Ipsum is simply dummy text</span><span >printing and typesetting industry</span><span >nothing</span><span >That's a big one!</span>
Note that if your actual strings after the #[number] NEVER have # symbols in it you can DRAMATICALLY improve the regex performance by using a greedy negated character class as the second capture group. #(\d )([^#] ) This reduces the step count from 283 steps to just 16 steps on your sample string.
To be perfectly honest, even a lazy pattern like #(\d )(. ?(?=#\d|$)) will process the sample string in 213 steps. Performance might not be a factor, so use whatever regex you are most comfortable reading.