I would like to reformat a dataframe so that each set of duplicate values in column one is replaced with a single header, which is then placed on its own row with the relevant data from columns two and three placed underneath it.
Here's what my current dataframe looks like:
df = pd.DataFrame({
'Dups': ['Invoices-Invoices', 'Invoices-Invoices', 'Contracts-Invoices', 'Contracts-Contracts', 'Contracts-Contracts'],
'FileOne': ['C:\text1.doc', 'C:\text2.doc', 'C:\text3.doc', 'C:\text4.doc', 'C:\text5.doc'],
'FileTwo': ['C:\doc1.doc', 'C:\doc2.doc', 'C:\doc3.doc', 'C:\doc4.doc', 'C:\doc5.doc']
})
Here is what I would like my dataframe to look like:
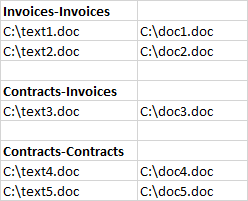
I've tried df.pivot(), df.melt(), and df.stack(). These approaches rearrange the data but not in the way that I am looking for.
Update thanks to Baron Legendre:
df['Files'] = df['FileOne'] "-" df['FileTwo']
df = df.melt(id_vars='Dups', value_vars=['Files']).groupby(['Dups', 'variable']).agg(list)
for header in df:
for item in df['value']:
print('header')
for x in item:
print(x)
Just trying to figure out how to print the headers, then move the whole thing to a csv.
CodePudding user response:
df.melt(id_vars='Dups', value_vars=['FileOne', 'FileTwo']).groupby(['Dups', 'variable']).agg(list)

df.groupby('Dups').agg(list)
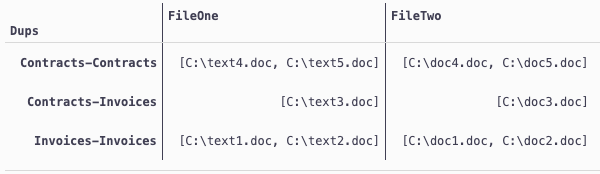
If you don't like list
og = df.groupby('Dups').agg(list)
df1 = og.FileOne.apply(pd.Series)
df2 = og.FileTwo.apply(pd.Series)
df1.columns = ['FileOne'] * len(df1.columns)
df2.columns = ['FileTwo'] * len(df2.columns)
df3 = pd.concat([df1, df2], axis=1).fillna('')
df3

If you want columns having suffix:
df1 = og.FileOne.apply(pd.Series)
df2 = og.FileTwo.apply(pd.Series)
df1.columns = ['FileOne_' str(i) for i in df1.columns]
df2.columns = ['FileTwo_' str(i) for i in df2.columns]
df3 = pd.concat([df1, df2], axis=1).fillna('')
df3

Another idea,
mt = df.melt(id_vars='Dups', value_vars=['FileOne', 'FileTwo'])
mt['ct'] = mt.groupby(['Dups','variable']).cumcount()
mt.pivot_table(index=['Dups','ct'], columns='variable', values='value', aggfunc=lambda x: x.unique()[0])
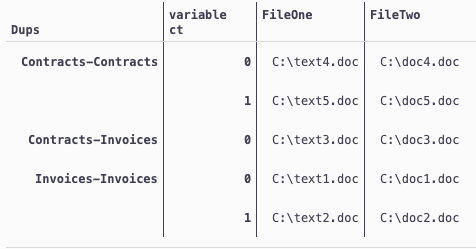
CodePudding user response:
import pandas as pd
df = pd.DataFrame({
'Dups': ['Invoices-Invoices', 'Invoices-Invoices', 'Contracts-Invoices', 'Contracts-Contracts', 'Contracts-Contracts'],
'FileOne': ['C:\text1.doc', 'C:\text2.doc', 'C:\text3.doc', 'C:\text4.doc', 'C:\text5.doc'],
'FileTwo': ['C:\doc1.doc', 'C:\doc2.doc', 'C:\doc3.doc', 'C:\doc4.doc', 'C:\doc5.doc']
})
mylist = df['Dups'].tolist()
mylist = list(dict.fromkeys(mylist))
# print(mylist)
df['Files'] = df['FileOne'] "-" df['FileTwo']
finalList = []
for x in mylist:
finalList.append("")
finalList.append(x)
for i in range(len(df)):
if df.loc[i, "Dups"] == x:
finalList.append(df.loc[i, "Files"])
print(finalList)
df = pd.DataFrame(finalList)
df.to_csv("NamesOfDuplicates2.csv")
CodePudding user response:
Your original dataframe is already close to the desired state. All is left is to add the group subheaders on top of values:
dups = pd.Series(df['Dups'].unique())
header_df = pd.DataFrame({
'Dups': dups,
'FileOne': dups,
'FileTwo': pd.Series([], dtype=str)
}).fillna({'FileTwo': ''})
output_df = pd.concat([df.assign(level=1), header_df.assign(level=0)]).sort_values(['Dups', 'level']).reset_index(drop=True).iloc[:, -3:-1]
output_df
FileOne FileTwo
0 Contracts-Contracts
1 C:\text4.doc C:\doc4.doc
2 C:\text5.doc C:\doc5.doc
3 Contracts-Invoices
4 C:\text3.doc C:\doc3.doc
5 Invoices-Invoices
6 C:\text1.doc C:\doc1.doc
7 C:\text2.doc C:\doc2.doc