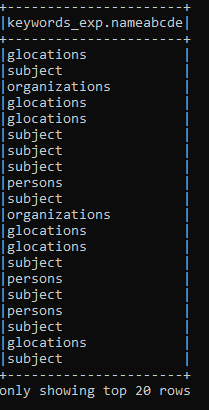
I am trying to create a dataframe out of a nested JSON structure, but I am encountering a problem that I dont understand. I have exploded an array-of-dicts structure in the JSON and now I am trying to access these dicts and create columns with the values in there. This is how the dicts look like:
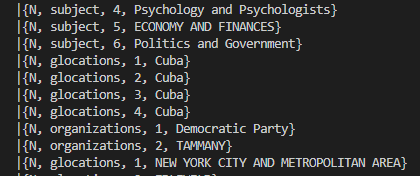
The values at index 1 (subject, glocations etc.) go under the key "name" according to the schema:
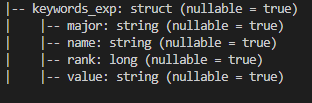
However, when I try:
dataframe = dataframe.withColumn("keywords_name", dataframe.keywords_exp.name)
it throws error "PySpark: TypeError: col should be Column". There is no such problem with any other of the keys in the dict, i.e. "value". I really do not understand the problem, do I have to assume that there are inconsistencies in the data? If yes, can you recommend a way to check for or even dodge them?
Thanks a lot in advance!
Edit: Khalid had the good idea to pre-define the schema. I tried to do so by storing one of the JSON files as a kind of default file. From that file, I wanted to extract the schema as follows:
schemapath = 'default_schema.json'
with open(schemapath) as f:
d = json.load(f)
schemaNew = StructType.fromJson(d)
responseDf = spark.read.schema(schemaNew).json("apiResponse.json", multiLine=True)
however, line
schemaNew = StructType.fromJson(d)
throws following error:
KeyError: 'fields'
No idea, where this 'fields' is coming from...
CodePudding user response:
Try setting scheme before reading. Edit: I think the json schema needs to be in specific format. I know it's not documented very well, but you can extract an example using .json() method to see the format and then adjust your schema files. See below updated example:
aa.json
[{"keyword_exp": {"name": "aa", "value": "bb"}}, {"keyword_exp": {"name": "oo", "value": "ee"}}]
test.py
from pyspark.sql.session import SparkSession
import json
if __name__ == '__main__':
spark = SparkSession.builder.appName("test-app").master("local[1]").getOrCreate()
from pyspark.sql.types import StructType, StructField, StringType
schema = StructType([
StructField('keyword_exp', StructType([
StructField('name', StringType(), False),
StructField('value', StringType(), False),
])),
])
json_str = schema.json()
json_obj = json.loads(json_str)
# Save output of this as file
print(json_str)
# Just to see it pretty
print(json.dumps(json_obj, indent=4))
# Save to file
with open("file_schema.json", "w") as f:
f.write(json_str)
# Load
with open("file_schema.json", "r") as f:
scheme_obj = json.loads(f.read())
# Re-load
loaded_schema = StructType.fromJson(scheme_obj)
df = spark.read.json("./aa.json", schema=schema)
df.printSchema()
df = df.select("keyword_exp.name", "keyword_exp.value")
df.show()
output:
{"fields":[{"metadata":{},"name":"keyword_exp","nullable":true,"type":{"fields":[{"metadata":{},"name":"name","nullable":false,"type":"string"},{"metadata":{},"name":"value","nullable":false,"type":"string"}],"type":"struct"}}],"type":"struct"}
{
"fields": [
{
"metadata": {},
"name": "keyword_exp",
"nullable": true,
"type": {
"fields": [
{
"metadata": {},
"name": "name",
"nullable": false,
"type": "string"
},
{
"metadata": {},
"name": "value",
"nullable": false,
"type": "string"
}
],
"type": "struct"
}
}
],
"type": "struct"
}
root
|-- keyword_exp: struct (nullable = true)
| |-- name: string (nullable = true)
| |-- value: string (nullable = true)
---- -----
|name|value|
---- -----
| aa| bb|
| oo| ee|
---- -----
CodePudding user response:
the Spark API seems to have problems with certain protected words. I came across this link when googling the error message
AttributeError: ‘function’ object has no attribute