This is my initial dataframe:
columns = ["CounterpartID","Year","Month","Day","churnprobability", "deadprobability"]
data = [(1234, 2021,5,12, 0.85,0.6),(1224, 2022,6,12, 0.75,0.6),(1345, 2022,5,13, 0.8,0.2),(234, 2021,7,12, 0.9,0.8)]
from pyspark.sql.types import StructType, StructField, IntegerType, DoubleType
schema = StructType([
StructField("client_id", IntegerType(), False),
StructField("year", IntegerType(), False),
StructField("month", IntegerType(), False),
StructField("day", IntegerType(), False),
StructField("churn_probability", DoubleType(), False),
StructField("dead_probability", DoubleType(), False)
])
df = spark.createDataFrame(data=data, schema=schema)
df.printSchema()
df.show(truncate=False)
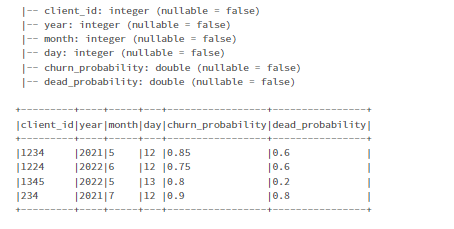
Then I do some transformations on the columns (basically, separating out the float columns into before decimals and after decimals columns) to get the intermediary dataframe.
abc = df.rdd.map(lambda x: (x[0],x[1],x[2],x[3],int(x[4]),int(x[4]%1 * pow(10,9)), int(x[5]),int(x[5]%1 * pow(10,9)) )).toDF(['client_id','year', 'month', 'day', 'churn_probability_unit', 'churn_probability_nano', 'dead_probability_unit', 'dead_probability_nano'] )
display(abc)

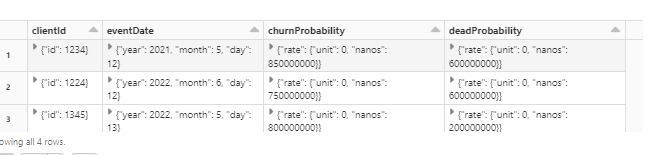
Below is the final desired dataframe (this is just an example of one row, but of course I'll need all the rows from the intermediary dataframe.
sjson = {"clientId": {"id": 1234 },"eventDate": {"year": 2022,"month": 8,"day": 5},"churnProbability": {"rate": {"units": "500","nanos": 780000000}},"deadProbability": {"rate": {"units": "500","nanos": 780000000}}}
df = spark.read.json(sc.parallelize([sjson])).select("clientId", "eventDate", "churnProbability", "deadProbability")
display(df)

How do I reach this end state from the intermediary state efficiently for all rows?
End goal is to use this final dataframe to write to Kafka where the schema of the topic is a form of the final desired dataframe.
CodePudding user response:
So, I was able to solve this using structs , without using to_json
import pyspark.sql.functions as f
defg = abc.withColumn(
"clientId",
f.struct(
f.col("client_id").
alias("id")
)).withColumn(
"eventDate",
f.struct(
f.col("year").alias("year"),
f.col("month").alias("month"),
f.col("day").alias("day"),
)
).withColumn(
"churnProbability",
f.struct( f.struct(
f.col("churn_probability_unit").alias("unit"),
f.col("churn_probability_nano").alias("nanos")
).alias("rate")
)
).withColumn(
"deadProbability",
f.struct( f.struct(
f.col("dead_probability_unit").alias("unit"),
f.col("dead_probability_nano").alias("nanos")
).alias("rate")
)
).select ("clientId","eventDate","churnProbability", "deadProbability" )
CodePudding user response:
I would probably eliminate the use of rdd logic (and again toDF) by using just one select from your original df:
from pyspark.sql import functions as F
defg = df.select(
F.struct(F.col('client_id').alias('id')).alias('clientId'),
F.struct('year', 'month', 'day').alias('eventDate'),
F.struct(
F.struct(
F.floor('churn_probability').alias('unit'),
(F.col('churn_probability') % 1 * 10**9).cast('long').alias('nanos')
).alias('rate')
).alias('churnProbability'),
F.struct(
F.struct(
F.floor('dead_probability').alias('unit'),
(F.col('dead_probability') % 1 * 10**9).cast('long').alias('nanos')
).alias('rate')
).alias('deadProbability'),
)
defg.show()
# -------- ------------- ---------------- ----------------
# |clientId| eventDate|churnProbability| deadProbability|
# -------- ------------- ---------------- ----------------
# | {1234}|{2021, 5, 12}|{{0, 850000000}}|{{0, 600000000}}|
# | {1224}|{2022, 6, 12}|{{0, 750000000}}|{{0, 600000000}}|
# | {1345}|{2022, 5, 13}|{{0, 800000000}}|{{0, 200000000}}|
# | {234}|{2021, 7, 12}|{{0, 900000000}}|{{0, 800000000}}|
# -------- ------------- ---------------- ----------------