I have a data frame like this:
df:
ID Award Award_ID
1 Ninja N13
1 Ninja N19
1 Warrior W16
2 Alpha A99
2 Delta D18
3 Alpha A101
3 Alpha A102
3 Alpha A103
4 Delta D12
Some of the IDs are repeated here. Whenever the ID has multiple occurrences, I want to make it into a single row by collating all the Award & Award_ID information in this format:
ID Multiple_Awards(Award_Names) Award(Award_IDs)
So, the expected output is:
df:
ID Award Award_ID
1 Multiple_Award(Ninja, Warrior) Ninja(N13, N19), Warrior(W16)
2 Multiple_Award(Alpha, Delta) Alpha(A99), Delta(D18)
3 Multiple_Award(Alpha) Alpha(A101,A102,A103)
4 Delta D12
In the case of a single award, I want the row to remain the same.
Can anyone help how to get the data into this format?
CodePudding user response:
Check Below code:
def custom_agg(val):
return val.unique() if val.count()<2 else 'Multiple_Award' str(tuple(val.unique()))
def custom_agg_1(val):
return str(tuple(val.unique()))
df.assign(Award_ID = df.groupby(['Id','Award'])['Award_ID'].transform(custom_agg_1),
Award_count = df.groupby(['Id'])['Award_ID'].transform('count')
).\
assign(Award_ID=lambda x: x.apply(lambda x: (x.Award x.Award_ID) if x.Award_count > 1 else x.Award_ID.replace(')','').replace(',','').replace('(',''), axis=1)).\
assign(Award=lambda x: x.groupby('Id')['Award'].transform(custom_agg)).\
groupby(['Id','Award']).agg({'Award_ID':custom_agg_1}).reset_index().\
assign(Award_ID = lambda x: x.Award_ID.str[2:-2].str.replace('"', '').replace({'\'': ''}, regex=True).replace({',\)': ')'}, regex=True),
Award = lambda x: x.Award.replace({'\'': ''}, regex=True).replace({',\)': ')'}, regex=True))
Output:
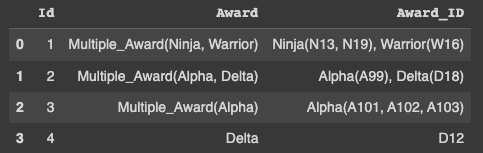
CodePudding user response:
You can do:
df1 = df.groupby(['ID', 'Award'],as_index=False)['Award_ID'].agg(tuple)
df1 = df1.groupby('ID').agg(tuple)
df1['Award_ID'] = df1[['Award', 'Award_ID']].apply(
lambda x: tuple(a str(b) for a, b in zip(x['Award'], x['Award_ID'])), axis=1)
df1['Award'] = df.groupby('ID')['Award'].count().transform(
lambda x: 'Multiple_Award' if x > 1 else '') df1['Award'].astype(str)
print(df1):
Award Award_ID
ID
1 Multiple_Award('Ninja', 'Warrior') (Ninja('N13', 'N19'), Warrior('W16',))
2 Multiple_Award('Alpha', 'Delta') (Alpha('A99',), Delta('D18',))
3 Multiple_Award('Alpha',) (Alpha('A101', 'A102', 'A103'),)
4 ('Delta',) (Delta('D12',),)