df1 is this:
accel_name numb frequency resistance phase
idx
3 K 0 -33 1 4030
4 K 1 -16 2 4028
5 K 2 -18 12 4036
6 K 3 -14 -3 4054
12 K 4 -2 17 4048
13 K 5 -18 12 4048
df2 is this:
accel_name numb frequency resistance phase
idx
7 P 0 -452 4089 329
8 P 1 -428 4082 427
9 P 2 -382 4078 518
10 P 3 -363 4052 545
11 P 4 -347 4064 508
14 P 5 -373 4068 409
output :
- append df2 columns to df1
- output frequency.csv, resistance.csv, phase.csv
CodePudding user response:
You can use df.to_csv() to export the relevant dataframes
df = pd.concat([df1, df2], axis=0).sort_index()
cols = ['frequency', 'resistance', 'phase']
for col in cols:
df[[col]].to_csv(col '.csv')
accel_name numb frequency resistance phase
idx
3 K 0 -33 1 4030
4 K 1 -16 2 4028
5 K 2 -18 12 4036
6 K 3 -14 -3 4054
7 P 0 -452 4089 329
8 P 1 -428 4082 427
9 P 2 -382 4078 518
10 P 3 -363 4052 545
11 P 4 -347 4064 508
12 K 4 -2 17 4048
13 K 5 -18 12 4048
14 P 5 -373 4068 409
Output:
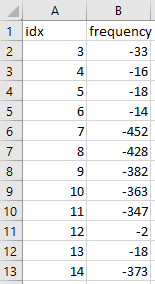
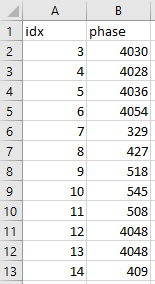
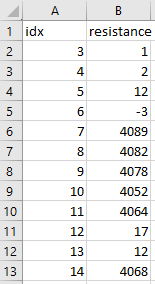
CodePudding user response:
import pandas as pd
phase = df1['phase']
phase2 = df2['phase']
phases = pd.concat([phase, phase2])
phasees.to_csv('phase_data.csv')
CodePudding user response:
IIUC, use a loop on the concatenated dataframes, slice columns using set operations:
cols = {'frequency', 'resistance', 'phase'}
df = pd.concat([df1, df2])
for c in cols:
df.drop(columns=cols.difference([c])).to_csv(f'{c}.csv')
example, frequency.csv:
,accel_name,numb,frequency
3,K,0,-33
4,K,1,-16
5,K,2,-18
6,K,3,-14
12,K,4,-2
13,K,5,-18
7,P,0,-452
8,P,1,-428
9,P,2,-382
10,P,3,-363
11,P,4,-347
14,P,5,-373