I want to make a loop to add new columns to a dataframe.
each time it adds a new column , I want to generate the values in the column using lambda function.
The function I wish to pass in the lambda is the function calcOnOff(). This function has 4 parameters :
v3proba, is the value of another column of this same row
on_to_off, is the current val of the loop iterator
off_to_on, is the current val of the second loop iterator
prevOnOff, is the value of this same column on the previous row.
Here is my code below
import pandas as pd
# I create a simple dataframe
dataExample={'Name':['Karan','Rohit','Sahil','Aryan','dex'],'v3proba':[0.23,0.42,0.51,0.4,0.7]}
dfExample=pd.DataFrame(dataExample)
# func to be applied on each new column of the dataframe
def calcOnOff(v3proba, on_to_off, off_to_on, prevOnOff):
if(prevOnOff == "OFF" and (v3proba*100) >= off_to_on ):
return "ON"
elif(prevOnOff == "OFF" and (v3proba*100) < off_to_on ):
return "OFF"
elif(prevOnOff == "ON" and (v3proba*100) < on_to_off ):
return "OFF"
elif(prevOnOff == "ON" and (v3proba*100) >= on_to_off ):
return "ON"
else:
return "ERROR"
# my iterators
off_to_on = 50
on_to_off = 49
# loops to generate new columns and populate col values
for off_to_on in range(50,90):
for on_to_off in range(10,49):
dfExample[str(off_to_on) '-' str(on_to_off)] = dfExample.apply(lambda row: calcOnOff(row['v3proba'], on_to_off, off_to_on, row[str(off_to_on) '-' str(on_to_off)].shift()), axis=1)
dfExample
The expected output would be a table with arround 1500 columns that look like this :
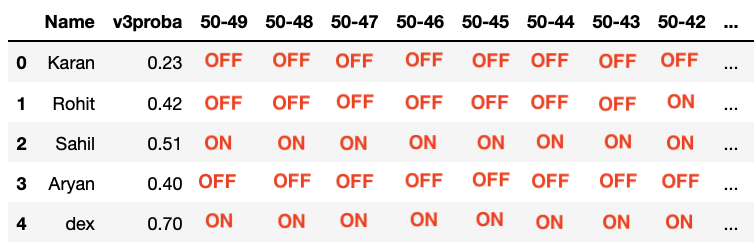
I think the problem in my algo is how to handle the first row as .shift() will look for an inexistant row?
Any idea what I am doing wrong?
CodePudding user response:
Preliminary remarks
- You can't address the field before it's created. So the code
row[f'{off_to_on}-{on_to_off}'].shift()won't work, you'll get aKeyErrorhere. - I guess, you want to shift down one row along the column by expression
row[...].shift(). It doesn't work like that.row[...]returns a value, which is contained in a cell, not the column. - It's not clear what should be the previous state for the very first row. What is the value of
prevOnOffparameter in this case?
How to fill in the column taking into account previous calculations
Let's use generators for this purpose. They can keep the inner state, so we can reuse a previously calculated value to get the next one.
But first, I'm gonna clarify the logic of calcOnOff. As I can see, it returns On if proba >= threshold or Off otherwise, where threshold is on_off if previous == On or off_on otherwise. So we can rewrite it like this:
def calcOnOff(proba, on_off, off_on, previous):
threshold = on_off if previous == 'On' else off_on
return 'On' if proba >= threshold else 'Off'
Next, let's transform previous to boolean and calcOnOff into a generator:
def calc_on_off(on_off, off_on, prev='Off'):
prev = prev == 'On'
proba = yield
while True:
proba = yield 'On' if (prev:=proba >= (on_off if prev else off_on)) else 'Off'
Here I made an assumption that the initial state is Off (default value of prev), and assume that previous value was On if prev == True or Off otherwise.
Now, I suggest to use itertools.product in order to generate parameters on_off and off_on. For each pair of these values we create an individual generator:
calc = calc_on_off(on_off, off_on).send
calc(None) # push calc to the first yield
This we can apply to the 100 * df['v3proba']:
proba = 100*df['v3proba']
df[...] = proba.apply(calc)
Full code
import pandas as pd
from itertools import product
data = {
'Name': ['Karan','Rohit','Sahil','Aryan','dex'],
'v3proba': [0.23,0.42,0.51,0.4,0.7]
}
df = pd.DataFrame(data)
def calc_on_off(on_off, off_on, prev='Off'):
prev = prev == 'On'
proba = yield
while True:
prev = proba >= (on_off if prev else off_on)
proba = yield 'On' if prev else 'Off'
proba = 100*df.v3proba
on_off = range(10, 50)
off_on = range(50, 90)
for state in product(on_off, off_on):
calc = calc_on_off(*state).send
calc(None)
name = '{1}-{0}'.format(*state) # 0:on_off, 1:off_on
df[name] = proba.apply(calc)
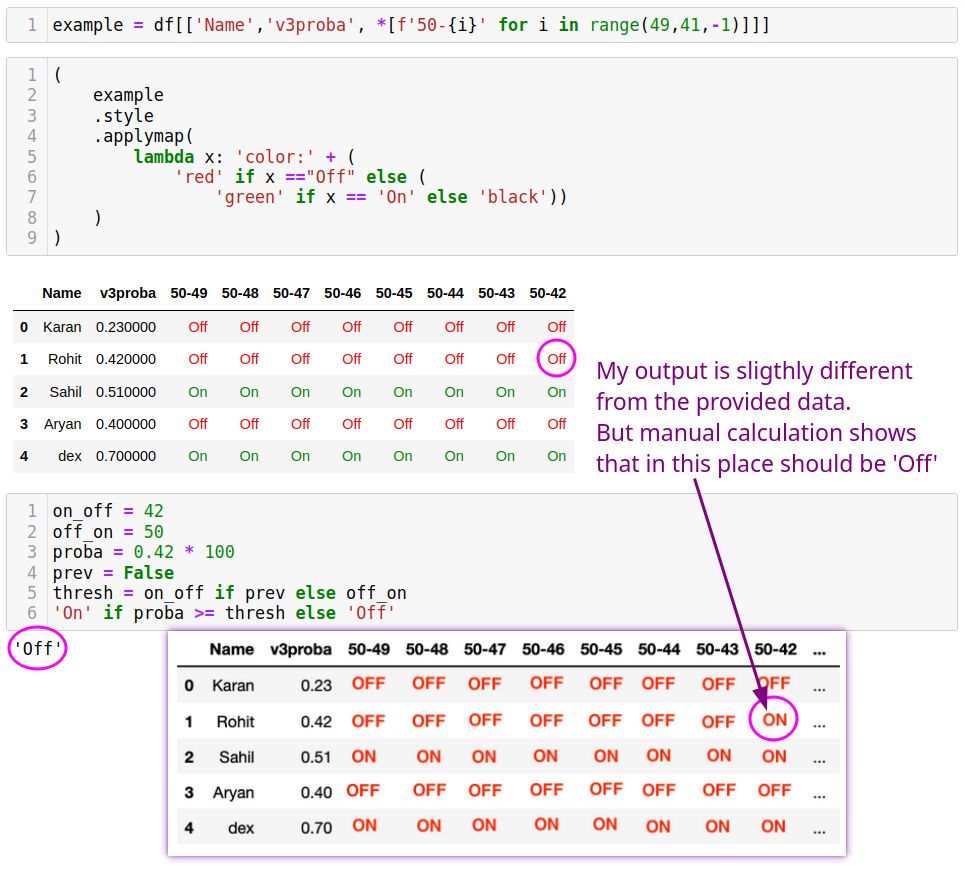
Update: Comparing with the provided expected result
P.S. No Generators
What if I don't want to use generators? Then we have somehow keep intermediate output outside the function. Let's do it with globals:
def calc_on_off(proba):
# get data outside
global prev, on_off, off_on
# save data outside
prev = proba >= (on_off if prev else off_on)
return 'On' if prev else 'Off'
default_state = 'Off'
proba = 100*df.v3proba
r_on_off = range(10, 50)
r_off_on = range(50, 90)
for on_off, off_on in product(r_on_off, r_off_on):
prev = default_state
df[f'{off_on}-{on_off}'] = proba.apply(calc_on_off)