I have this matrix that I want to convert into a column with the counts of each cell that matches its respective column that allows me to quantify the quantity of each type of car.
library(tidyverse)
colsgroup <- read_csv("colsgroup.csv")
typeof(colsgroup)
colsgroup$car <- gsub("[|]", ",", colsgroup$car) %>%
as.data.frame() %>%
separate(1L,
into = c("car_1","car_2","car_3","car_4","car_5","car_6","car_7","car_8"), sep = ",") %>%
mutate_all(as.character)
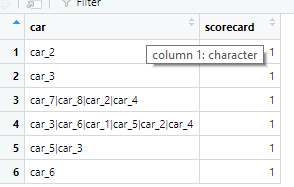
this is the result

this is what i want to get, much like to use pivot_wider

CodePudding user response:
It may be easier with dummy_cols
library(fastDummies)
library(dplyr)
library(stringr)
dummy_cols(colsgroup, 'car', split= "\\|") %>%
rename_with(~ str_remove(.x, "car_"), starts_with('car_'))%>%
select(car, scorecard, order(readr::parse_number(names(.)[-(1:2)])) 2)
-output
# A tibble: 6 × 10
car scorecard car_1 car_2 car_3 car_4 car_5 car_6 car_7 car_8
<chr> <dbl> <int> <int> <int> <int> <int> <int> <int> <int>
1 car_2 1 0 1 0 0 0 0 0 0
2 car_3 1 0 0 1 0 0 0 0 0
3 car_7|car_8|car_2|car_4 1 0 1 0 1 0 0 1 1
4 car_3|car_6|car_1|car_5|car_2|car_4 1 1 1 1 1 1 1 0 0
5 car_5|car_3 1 0 0 1 0 1 0 0 0
6 car_6 1 0 0 0 0 0 1 0 0
CodePudding user response:
Use separate_rows function instead of separate, then convert long table to wide.
library(tidyverse)
colsgroup <- read_csv("colsgroup.csv") %>%
rowid_to_column() %>% # remember the original row
separate_rows(car, sep = "\\|") %>%
spread(car, scorecard)