I am looking to get a series/DataFrame of IDs that have only NAs within the data.
The data looks something like this:
| ID | Score | Date |
|---|---|---|
| 1 | 95 | 1-1-2022 |
| 1 | nan | 1-1-2022 |
| 1 | nan | 2-1-2022 |
| 2 | nan | 1-1-2022 |
| 2 | 100 | 2-1-2022 |
| 3 | nan | 1-1-2022 |
| 3 | nan | 1-1-2022 |
| 3 | nan | 2-1-2022 |
So in this case, I would only want to grab ID 3 and have one instance of it in the newly created DF.
So far, I've tried:
df = pd.DataFrame({'ID':[1,1,1,2,2,3,3,3],
'Score':[95,nan,nan,nan,100,nan,nan,nan],
'Date':['1-1-2022','1-1-2022','2-1-2022','1-1-2022','2-1-2022',
'1-1-2022','1-1-2022', '2-1-2022']})
df2 = pd.DataFrame(df.groupby('ID',dropna=False)['Score'].count())
df3 = df2[df2['Score'] == 0]
But this does not seem to work. Thanks for your help.
CodePudding user response:
You could create a boolean vector checking if 'Score' column is nan and then you can groupby your 'ID' column and use transform('all').
This will return True / False to all rows of the ID that are nan in all rows.
>>> df['Score'].isna().groupby(df['ID']).transform('all')
0 False
1 False
2 False
3 False
4 False
5 True
6 True
7 True
Name: Score, dtype: bool
Using this boolean you can filter your dataframe and get ID 3 in a new df:
ids_with_all_none = df[df['Score'].isna().groupby(df['ID']).transform('all')]
ID Score Date
5 3 NaN 1-1-2022
6 3 NaN 1-1-2022
7 3 NaN 2-1-2022
CodePudding user response:
I dont know if this is what you mean exactly, if not please provide what you expect as ouput. But to select the rows with Nans for the score you can use:
df2 = df.loc[df.Score.isna()]
output:
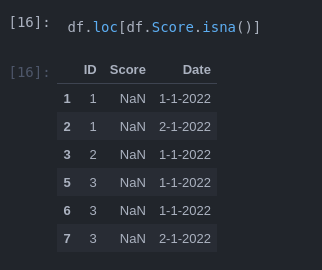
the you can select the IDs simply with:
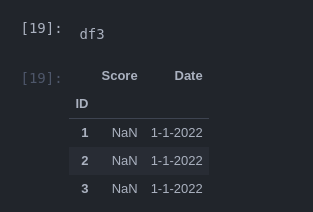
df3 = df2.groupby('ID').first()
df3
output:
CodePudding user response:
It is going to work fine if you replace nan with None. Try this out:
df = pd.DataFrame({'ID':[1,1,1,2,2,3,3,3],
'Score':[95,None,None,None,100,None,None,None],
'Date':['1-1-2022','1-1-2022','2-1-2022','1-1-2022','2-1-2022',
'1-1-2022','1-1-2022', '2-1-2022']})
df2 = pd.DataFrame(df.groupby('ID',dropna=False, as_index=False)['Score'].count())
df3 = df2[df2['Score'] == 0]
print(df3['ID'])