My goal with this code is to replace only the occurrences of a substring that are preceded and followed by a specific pattern (to establish that pattern I have come up with the use of RegEx)
Actually I have already tried in many ways and I have not got good results, here I have used the compile() method to compile the RegEx pattern found in the input string into a regex pattern object (basically I extract 'one by one the occurrences of the substring' that I want to modify that meet the conditions of the RegEx pattern).
Then I can simply use the replace() function to, forgive the redundancy, replace the extracted substrings with the substring that I want
import re
input_text = "y creo que hay 55 y 6 casas, y quizas alguna mas... yo creo que empezaria entre la 1 ,y las 27"
#the string with which I will replace the desired substrings in the original input string
content_fix = " "
##This is the regex pattern that tries to establish the condition in which the substring should be replaced by the other
#pat = re.compile(r"\b(?:previous string)\s*string that i need\s*(?:string below)?", flags=re.I, )
#pat = re.compile(r"\d\s*(?:y)\s*\d", flags=re.I, )
pat = re.compile(r"\d\s*(?:, y |,y |y )\s*(?:las \d|la \d|\d)", flags=re.I, )
x = pat.findall(input_text)
print(*map(str.strip, x), sep="\n") #it will print the substrings, which it will try to replace in the for cycle
content_list = []
content_list.append(list(map(str.strip, x)))
for content in content_list[0]:
input_text = input_text.replace(content, content_fix) # "\d y \d" ---> "\d \d"
print(repr(input_text))
This is the output that I get:
'y creo que hay 5 casas, y quizas alguna mas... yo creo que empezaria entre la 7'
And this is the correct output that I need:
'y creo que hay 55 6 casas, y quizas alguna mas... yo creo que empezaria entre la 1 27'
What changes should I make to my RegEx so that it extracts the correct substrings and suits the goals of this code?
CodePudding user response:
input_text = "y creo que hay 55 y 6 casas, y quizas alguna mas... \
yo creo que empezaria entre la 1 ,y las 27"
re.sub(r'((\d \s )y\s (\d ))| ((\d \s ),y\s \w{3}\s (\d ))', r'\2\3 \5\6', input_text)
y creo que hay 55 6 casas, y quizas alguna mas... yo creo que empezaria entre la 1 27
CodePudding user response:
I came up with something and this is the best I could get :). You may find a way to improve it. import re
input_text = "y creo que hay 55 y 6 casas, y quizas alguna mas... yo creo que empezaria entre la 1 ,y las 27"
print(re.sub(r"(?<=\d). ?(?=\d)", " ", input_text))
The output will look like this:
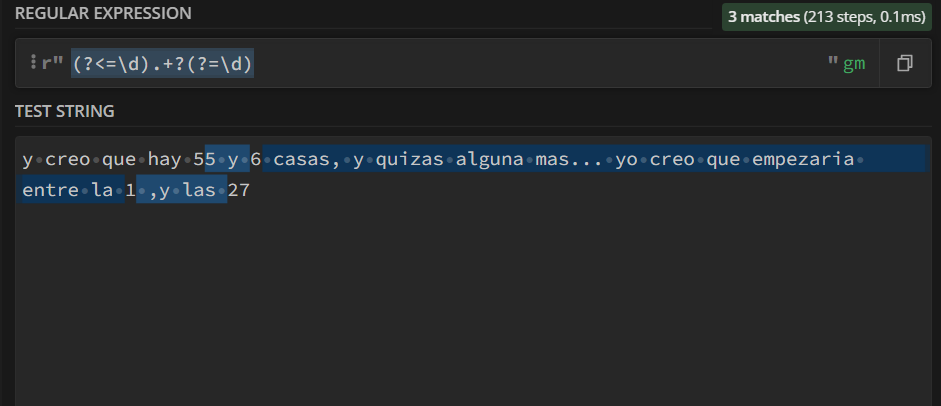
Maybe you will find a way to improve the expression or someone will..