My table has a nested object (record) with a few array (repeated) properties.
there are 4 properties that are nested:
BM.HISTORY.AutoBill.BaseRate
BM.HISTORY.AutoBill.Substatus
BM.HISTORY.AutoBill.Services
BM.HISTORY.AutoBill.Conditions
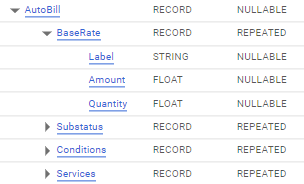
Each property contains data like these
[
{Label: "Completed....", Amount: 34.3, Quantity: 2},
{Label: "Completed....", Amount: 34.3, Quantity: 2}
,...]
I'd like to extract a simple flat csv like this
OrderId StartWindow Type Label Quantity Amount
123 2022-07-17 13:07:00 UTC BaseRate Completed @ 100% 0 82.6
123 2022-07-17 13:07:00 UTC Services service 1 1 16.1323
123 2022-07-17 13:07:00 UTC Services service 2 1 5
123 2022-07-17 13:07:00 UTC Conditions 10% Time Window Premium 0.826 8.26
234 2022-07-17 13:07:00 UTC BaseRate Completed @ 100% 0 3.6
234 2022-07-17 13:07:00 UTC Services service 1 1 16.1323
234 2022-07-17 13:07:00 UTC Services service 2 1 5
234 2022-07-17 13:07:00 UTC Conditions 10% Time Window Premium 0.826 8.26
- Where StartWindow is a simple field of my table.
- Type is a tag I create based on BILL.XXXX from the for properties above and the other 3 columns will be flattened records inside each array.
- they need to stack as rows
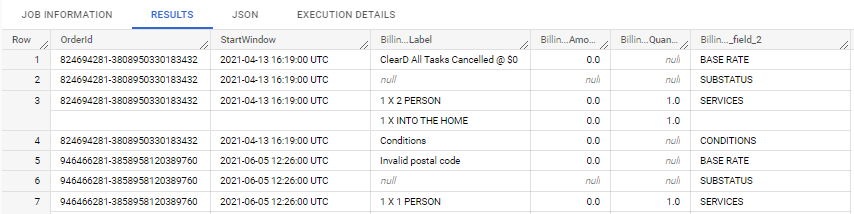
This is what I have done but I cannot flatten it all in a simple csv.
SELECT
Id as OrderId, StartWindow, Billing
FROM
`xxx.xxxx.xxDB ADDRESSxxx`,
UNNEST([
(BM.HISTORY.BILL.BaseRate,'BASE RATE'),
(BM.HISTORY.BILL.Substatus,'SUBSTATUS'),
(BM.HISTORY.BILL.Services,'SERVICES'),
(BM.HISTORY.BILL.Conditions,'CONDITIONS')
]
) as Billing
LIMIT 10
As you can see the result is not perfectly flattened.
CodePudding user response:
Your code
select x from
UNNEST([
([1,2,3],'BASE RATE'),
([5,6],'SUBSTATUS')
]) x
generates first an array of two entries and the unpacks it into two rows. The first column is an array, the other column is the string name.
Therefore, the first column needs to be unnested again. In the following example this is done by unnest(x.dataset) as dataset. The columns A to C correspond to BaseRate and Substatus.
With tbl as
(
Select 1 id, "name1" as name, [struct("label1" as label,500 as amount),("t",1)] A,[("B1",20)] B , [("C1",1)] C
union all select 2, "name2",[("A2",2)],[("B2",10)] , null
union all select 3,"-",[],null ,null
union all select 4,"-",[],null ,[("test4",100),("test5",500)]
)
Select id,type,dataset.* from tbl,
unnest([
struct(A as dataset,'A' as type),struct(B,'B'),struct(C,'C')
]) as x, unnest(x.dataset) as dataset
Another way of solving this task is to unnested each record by itself:
SELECT Id, BaseRate.*, Substatus, Services, Conditions
FROM `xxx.xxxx.xxDB ADDRESSxxx`,
UNNEST(BM.HISTORY.BILL.BaseRate) as BaseRate,
UNNEST(BM.HISTORY.BILL.Substatus) as Substatus,
UNNEST(BM.HISTORY.BILL.Services) as Services,
UNNEST(BM.HISTORY.BILL.Conditions) as Conditions
However, here all combination of all entries are given out.
Thus there is a joining needed as well and the unnest is to be combinded WITH OFFSET to obtain the entry number.
I will show the route on an easy example. The table tbl has an id column, the columns A and B contain records of values. The column C contains a record of struct. Thus your column BaseRate is column C.
Each row of the tbl table has to be shown several time, to include all entries of the columns A, B, C.
We query the table tbl and calculate the times this row has to be shown: The GREATEST for the array_lenght of the columns A, B, C gives this information. The unnest and generate_array duplicates the needed rows for each id and includes an entry column counting from zero upwards.
For column A the values are unnested and joined to the entry column. The same is done for the B and C column.
Due to the join to the entry column there are no combination between the entries of the differen columns.`
Since column C_ is a structure, C_.* unpacks this and gives all entries out directly.
With tbl as
(
Select 1 id, "name1" as name, [1,2,3,4,5] A,[10,11] B , [struct("label1" as label,500 as amount),("t",1)] C
union all select 2, "name2",[7,8],[20,21,22] , null
union all select 3,"-",[],null ,null
union all select 4,"-",[],null ,[("test",100),("test5",500)]
)
select id,entry,name,A_,B_ ,C_.*
from tbl,
unnest(generate_array(0,GREATEST(1,ifnull(array_length(A),0),ifnull(array_length(B),0),ifnull(array_length(C),0))-1)) as entry
left join
unnest(A) as A_ WITH OFFSET as A_offset
on A_offset=entry
left join
unnest(B) as B_ WITH OFFSET as B_offset
on B_offset=entry
left join
unnest(C) as C_ WITH OFFSET as C_offset
on C_offset=entry