I'm running a Spark application which load 1 million rows of data from a database into 201 partitions and then write as parquet files. The application code may look like:
dataframe = spark.read.format('jdbc').options(...).load()
dataframe_over_range = dataframe.filter("date >= '2017-01-01 00:00:00'")
if dataframe_over_range.head(1):
for date in dates: # dates was a list of date
dataframe_daily = dataframe_over_range.filter(f"date >= '{date} 00:00:00'").filter(f"date <= '{date} 23:59:59'")
dataframe_daily.write.parquet('s3://...', mode='overwrite')
But Spark always ends up with 200 task SUCCESS and 1 task FAILED:

The failed task got an java.lang.OutOfMemoryError: GC overhead limit exceeded in executor, and it had a long Scheduler Delay in Spark UI:
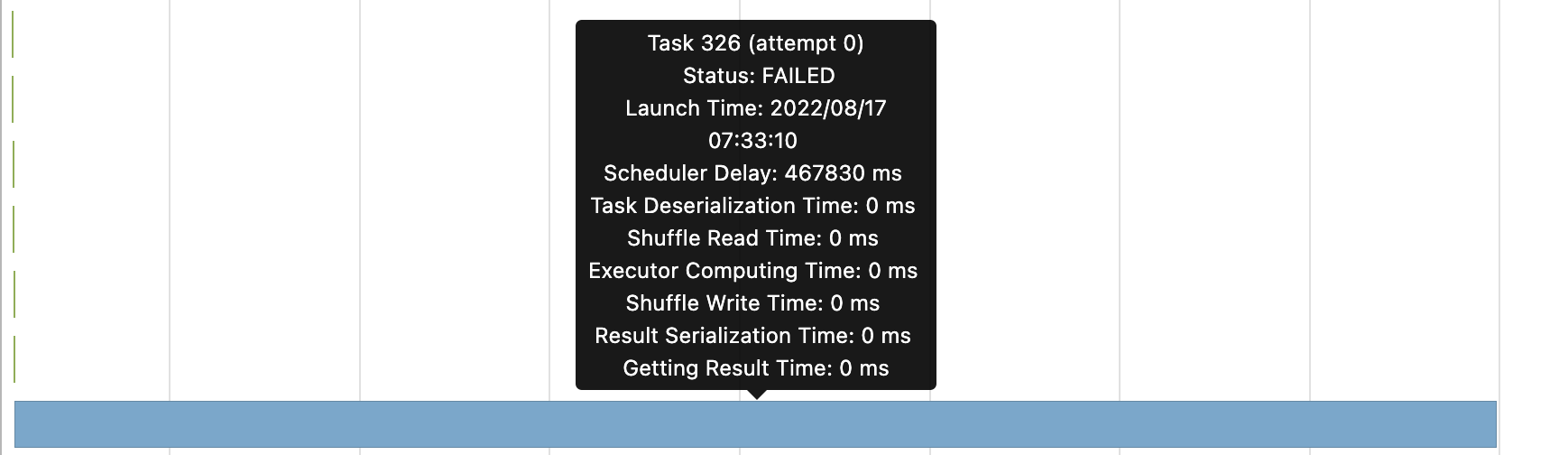
What may be the reason of this problem ?
==========Update==========
As @walking said, I change my code to this format:
from pyspark.sql.functions import date_format
dataframe = spark.read.format('jdbc').options(...).load()
dataframe_over_range = dataframe.filter("date >= '2017-01-01 00:00:00'")
if dataframe_over_range.head(1):
datafram_over_range.withColumn('partition_date', date_format(tb_config['date_col'], 'yyyy-MM-dd')).write.partitionBy('partition_date').parquet('s3://...')
But the problem was still the same, there's one task failed with long Scheduler Delay. But what makes me curious is that I found all parquet files were actually written to file system. What does Spark do after finish writing ?
==========Update 2==========
I've check the GC log of Spark, and I found the number of FinalReference and WeakReference grows after the failed task start, and also number of promoted grows too. This would lead to Full GC after few minutes, and finally too many Full GC leads to java.lang.OutOfMemoryError: GC overhead limit exceeded
CodePudding user response:
I've solved this problem. I'm using the jdbc options lowerBound and upperBound in a wrong way. This two options are only for data partition but not for filtering data from database, you should filter data via using subquery in dbtable option or query option.
For example, I want to load data which id between 0 and 1000000, and seperate into 10 partitions, the wrong way is:
spark.read.format('jdbc').options(
...,
dbtable='my_table',
partitionColumn='id',
lowerBound=0,
upperBound=1000000,
numPartitions=10
...
).load()
This would cause the query of the last partition be like select * from my_table where id >= 900000 which doesn't have upper bound. The right way should be:
spark.read.format('jdbc').options(
...,
dbtable='(select * from my_table where id between 0 and 1000000) t',
partitionColumn='id',
lowerBound=0,
upperBound=1000000,
numPartitions=10
...
).load()