I am working in pandas and want to drop few rows based on a sub condition.
Dataset
| System | Category |
|---|---|
| A | 1 |
| A | 2 |
| B | 1 |
| C | 1 |
| D | 1 |
| D | 2 |
| E | 2 |
| F | 2 |
| G | 1 |
I want to drop system rows having category value as 2 provided it(like A and D) has both category 1 and 2. If only category 2 alone is present for the system(like E and F), then no need to drop it.
Require output as below
| System | Category |
|---|---|
| A | 1 |
| B | 1 |
| C | 1 |
| D | 1 |
| E | 2 |
| F | 2 |
| G | 1 |
I tried pd.drop which has option to drop based on directly removing all system having category 2 but no option to provide a sub condition as explained above. Please suggest
CodePudding user response:
You can first sort the column(first by system then by category). Then remove the duplicate from System.
df.sort_values(['System', 'Category'], ascending=[True, True], inplace = True)
df.drop_duplicates(subset = ['System'], keep = 'first', inplace = True)
Output:
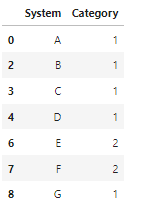
CodePudding user response:
You would want to remove rows with the conditions
- Length of
Systemgroup is > 1 and Categoryis 2
m = (df.groupby('System')['Category'].transform(len) > 1) & (df['Category'] == 2)
df = df[~m].reset_index(drop=True)
print(df):
System Category
0 A 1
1 B 1
2 C 1
3 D 1
4 E 2
5 F 2
6 G 1