I am working with a dataset that is of the form
stops stops name 0 1 2 3
1 A 21:09:00 17:24:00 17:54:00 17:29:00
2 B 21:10:00 17:25:00 17:55:00 17:27:00
3 C 17:28:00 17:58:00 17:26:00
4 D 21:16:00 18:01:00 17:23:00
5 E 21:17:00 17:32:00 18:02:00
6 F 21:20:00 17:35:00 18:05:00 17:20:00
I know how to sort columns [0-3] according to the times of a specific stop. For example, to sort based on the times of the first stop(A) I do below:
def time_to_seconds(time):
try:
h,m,s = time.split(':')
return int(h) * 3600 int(m) * 60 int(s)
except:
return -1
def time_cmp(l):
return [ time_to_seconds(time) for time in l ]
df[df.columns[2:]] = df[df.columns[2:]].sort_values(by=[0],axis=1,key=time_cmp)
It works, and values are stored:
stops stops name 0 1 2 3
1 A 17:24:00 17:29:00 17:54:00 21:09:00
2 B 17:25:00 17:27:00 17:55:00 21:10:00
3 C 17:28:00 17:26:00 17:58:00
4 D 17:23:00 18:01:00 21:16:00
5 E 17:32:00 18:02:00 21:17:00
6 F 17:35:00 17:20:00 18:05:00 21:20:00
However, I want to sort the columns based on the minimum value for each column, not a specific row(or stop). What should I do?
Result of the desired sort:
stops stops name 0 1 2 3
1 A 17:29:00 17:24:00 17:54:00 21:09:00
2 B 17:27:00 17:25:00 17:55:00 21:10:00
3 C 17:26:00 17:28:00 17:58:00
4 D 17:23:00 18:01:00 21:16:00
5 E 17:32:00 18:02:00 21:17:00
6 F 17:20:00 17:35:00 18:05:00 21:20:00
As you can see min value of column 0(17:20:00) is less than the min value of column 1(17:24:00).
CodePudding user response:
You can convert to_timedelta, then use numpy to get the sorted order:
import numpy as np
cols = df.columns[2:]
order = np.argsort(df[cols].apply(pd.to_timedelta).min())
df[cols].iloc[:, order]
# or as one-liner
# df[cols].iloc[:, np.argsort(df[cols].apply(pd.to_timedelta).min())]
output:
3 1 2 0
0 17:29:00 17:24:00 17:54:00 21:09:00
1 17:27:00 17:25:00 17:55:00 21:10:00
2 17:26:00 17:28:00 17:58:00 NaN
3 17:23:00 NaN 18:01:00 21:16:00
4 NaN 17:32:00 18:02:00 21:17:00
5 17:20:00 17:35:00 18:05:00 21:20:00
If you want to replace the values, keeping the column names intact:
cols = df.columns[2:]
order = np.argsort(df[cols].apply(pd.to_timedelta).min())
df[cols] = df[cols].iloc[:, order]
output:
stops stops name 0 1 2 3
0 1 A 17:29:00 17:24:00 17:54:00 21:09:00
1 2 B 17:27:00 17:25:00 17:55:00 21:10:00
2 3 C 17:26:00 17:28:00 17:58:00 NaN
3 4 D 17:23:00 NaN 18:01:00 21:16:00
4 5 E NaN 17:32:00 18:02:00 21:17:00
5 6 F 17:20:00 17:35:00 18:05:00 21:20:00
CodePudding user response:
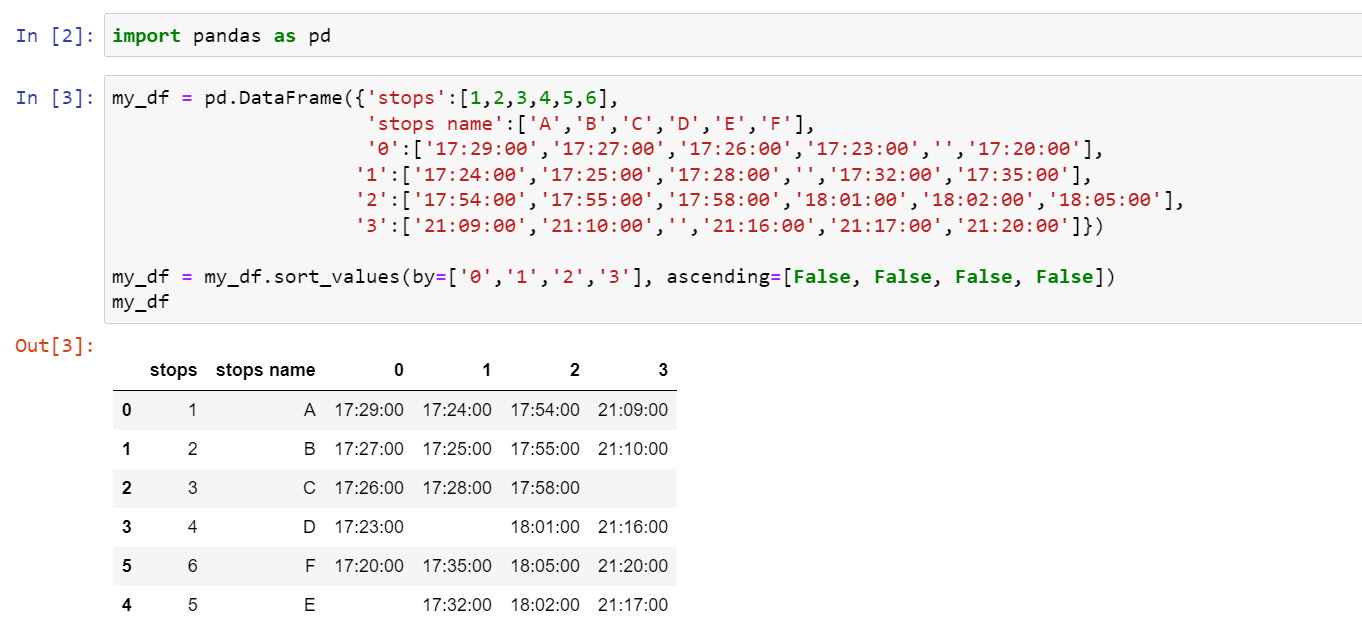
Here is how you can do it-
my_df = pd.DataFrame({'stops':[1,2,3,4,5,6],
'stops name':['A','B','C','D','E','F'],
'0':['17:29:00','17:27:00','17:26:00','17:23:00','','17:20:00'],
'1':['17:24:00','17:25:00','17:28:00','','17:32:00','17:35:00'],
'2':['17:54:00','17:55:00','17:58:00','18:01:00','18:02:00','18:05:00'],
'3':['21:09:00','21:10:00','','21:16:00','21:17:00','21:20:00']})
my_df = my_df.sort_values(by=['0','1','2','3'], ascending=[False, False, False, False])
my_df
Output-
stops stops name 0 1 2 3
0 1 A 17:29:00 17:24:00 17:54:00 21:09:00
1 2 B 17:27:00 17:25:00 17:55:00 21:10:00
2 3 C 17:26:00 17:28:00 17:58:00
3 4 D 17:23:00 18:01:00 21:16:00
5 6 F 17:20:00 17:35:00 18:05:00 21:20:00
4 5 E 17:32:00 18:02:00 21:17:00