I would like a lexer to parse a single named token in two ways -- as "itself" and then as an Identifier. This isn't possible (I don't think?) in Antlr4, so I'm curious what the suggested approach is to solving the following:
grammar Id;
root: itemList EOF;
itemList
: item (',' item)*
;
item
: literal
| identifier
;
literal
: TYPE? String
;
identifier: Identifier | TYPE; // This is the fix I'm using here...
TYPE: 'date' | 'timestamp';
String: '"' . ? '"';
Identifier: [a-zA-Z] ;
WHITESPACE: [ \t\r\n] -> skip;
For example, for input a,b,c,"hi",date "2020-01-01",k,date here is the parse tree:
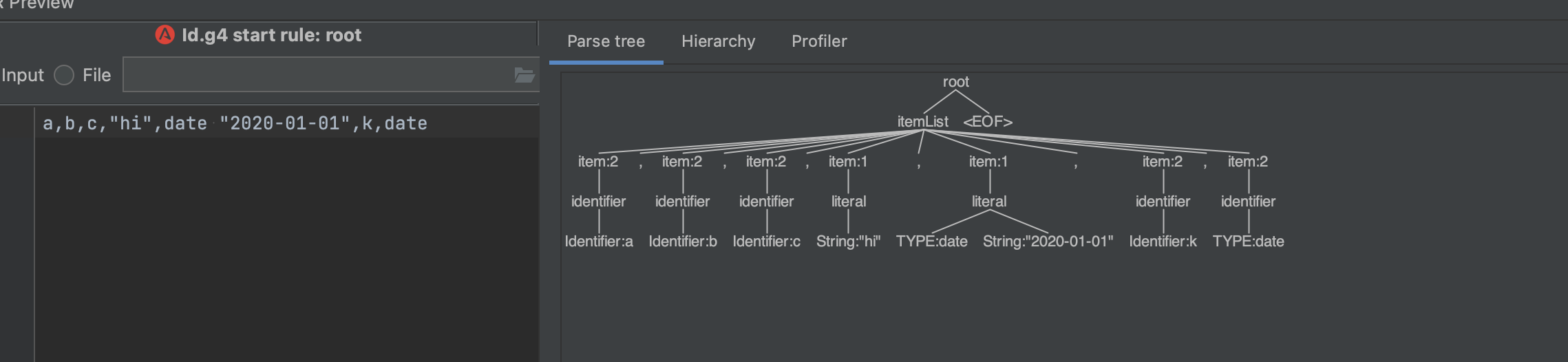
But this is a pretty 'ugly' parse tree to me, having an unnecessary node on every identifier. Is there a way to perhaps have a 'hidden' rule that captures it but doesn't add an extra node? I suppose the other way to do this is by in-lining the same thing over and over, but this seems to be very cumbersome, especially if there are a lot of types and it's done in a few places:
grammar Id;
root: itemList EOF;
itemList
: item (',' item)*
;
item
: literal
| (Identifier | 'date' | 'timestamp')
;
literal
: (Identifier | 'date' | 'timestamp')? String
;
TYPE: 'date' | 'timestamp';
String: '"' . ? '"';
Identifier: [a-zA-Z] ;
WHITESPACE: [ \t\r\n] -> skip;
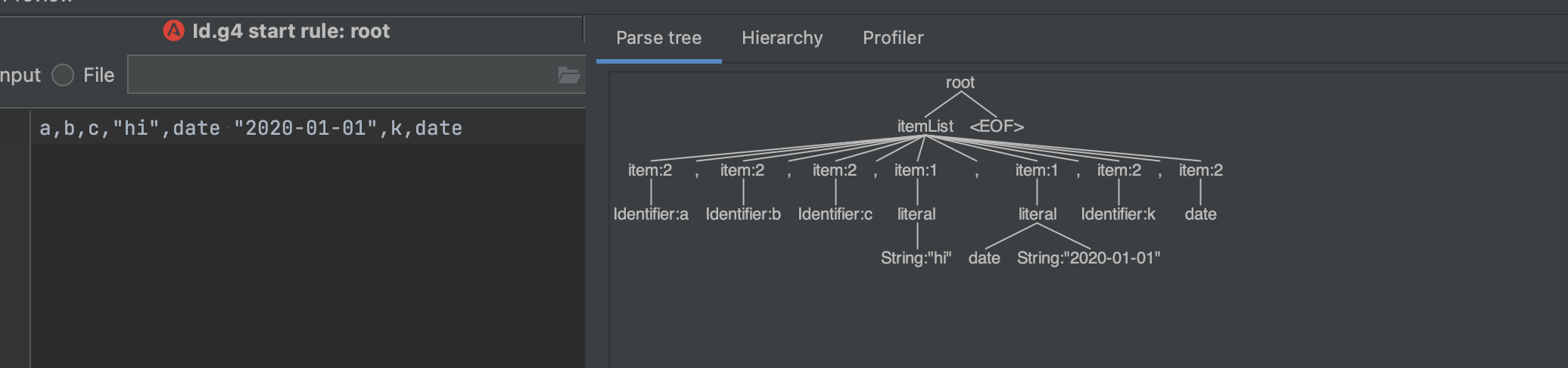
CodePudding user response:
This will give you a bit more compact tree:
grammar Id;
root: itemList EOF;
itemList
: item (',' item)*
;
item
: (Identifier | 'date' | 'timestamp')? String # literalItem
| (Identifier | 'date' | 'timestamp') # idItem
;
//literal
// : (Identifier | 'date' | 'timestamp')? String
// ;
TYPE: 'date' | 'timestamp';
String: '"' . ? '"';
Identifier: [a-zA-Z] ;
WHITESPACE: [ \t\r\n] -> skip;

There's no such thing as a "hidden" rule, so you have to pick your tradeoff. Reusable rules will create intermediate parse tree nodes. But they also allow you to avoid repetition.
Just opinion, but you can go too far either way. Too much factoring rules out can result in rather absurdly deep trees, but if you go too far the other way you can start losing information, and have grammar maintenance issues. Also opinion, but you may wish to spend some time writing listeners/visitors against your parse tree. I find that the intermediate nodes are not nearly so bothersome as I would have expected them to be (you can largely ignore them in listeners and visitors)