I am new to AWS Sagemaker and I wrote data to my S3 bucket. But these datasets also appear in the working tree of my jupyter instance.
How can I move data directly to S3 without saving it "locally"?
My code:
import os
import pandas as pd
import sagemaker, boto3
from sagemaker import get_execution_role
from sagemaker.inputs import TrainingInput
from sagemaker.serializers import CSVSerializer
# please provide your own bucket and folder path of your bucket here
bucket = "test-bucket2342343"
sm_sess = sagemaker.Session(default_bucket=bucket)
file_path = "Use Cases/Sagemaker Demo/xgboost"
# data
df_train = pd.DataFrame({'X':[0,100,200,400,450, 550,600,800,1600],
'y':[0,0, 0, 0, 0, 1, 1, 1, 1]})
df_test = pd.DataFrame({'X':[10,90,240,459,120, 650,700,1800,1300],
'y':[0,0, 0, 0, 0, 1, 1, 1, 1]})
# move to S3
df_train[['y','X']].to_csv('train.csv', header=False, index=False)
df_val = df_test.copy()
df_val[['y','X']].to_csv('val.csv', header=False, index=False)
boto3.Session().resource("s3").Bucket(bucket) \
.Object(os.path.join(file_path, "train.csv")).upload_file("train.csv")
boto3.Session().resource("s3").Bucket(bucket) \
.Object(os.path.join(file_path, "val.csv")).upload_file("val.csv")
It successfully appears in my S3 bucket.
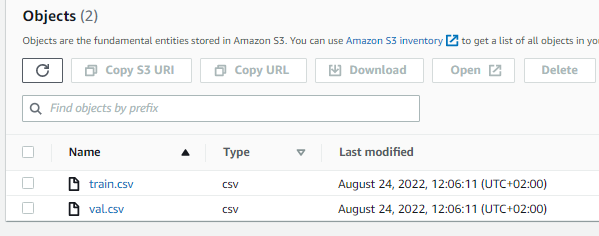
But it also appears here:
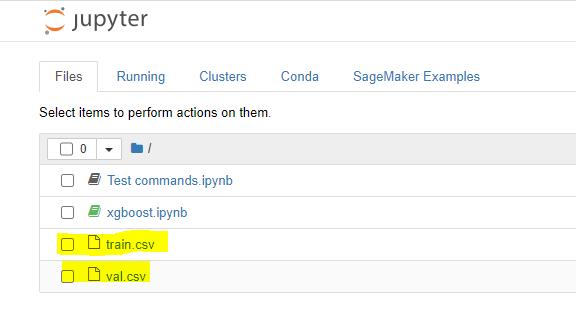
CodePudding user response:
with Pandas you can save to S3 directly (relevant answer). For example:
import pandas as pd
df = pd.DataFrame( [ [1, 1, 1], [2, 2, 2] ], columns=['a', 'b', 'c'])
df.to_csv('s3://test-bucket2342343//tmp.csv', index=False)
Or, use what you currently do and delete the local files:
import os
os.remove('train.csv')