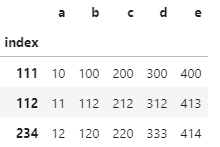
I have thousands of pandas dataframe df, each with 120 million rows that looks like this:
a b c d e
111 10 100 200 300 james
112 11 110 210 310 june
112 11 140 210 312 dune
234 12 120 220 333 dane
The repeating index is custom index is 112. I want to keep the row with maximum value for column 'b' along with the custom index '112'. So the output would look like
a b c d e
111 10 100 200 300 james
112 11 140 210 312 dune
234 12 120 220 333 dane
What would be a memory and speed efficient way to do this?
CodePudding user response:
You can try the following.
dupe_idx_rows = df[df.index.duplicated(keep=False)].sort_values(by='b', ascending=False)
dupe_idx_rows_one = dupe_idx_rows[~dupe_idx_rows.index.duplicated(keep='first')]
out= pd.concat([df[~df.index.duplicated(keep=False)],dupe_idx_rows_one])
Alternatively, you can also try using Groupby
CodePudding user response:
You can filter by the maximum value of a column in each group by using