I have the following string:
s = '[[[1],1,¬q,"A",[]],[[2],2,p→q,"A",[]],[[3],3,p,"A",[]],[[2,3],4,q,"→E",[2,3]],[[1,2,3],5,q∧ ¬q,"∧I",[1,4]],[[1,2],6,¬p,"¬I",[3,5]]]'
My aim now is to convert this into some pandas dataframe with columns:
df = pd.DataFrame(
columns=['Assumptions', 'Index', 'Proposition', 'Premisses', 'Rule'])
which can be illustrated in console as follows:
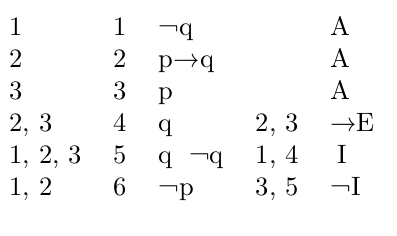
How can I do that?
CodePudding user response:
Looks like a case for regular expressions.
import re
from ast import literal_eval
import pandas as pd
s = ('[[[1],1,¬q,"A",[]],[[2],2,p→q,"A",[]],[[3],3,p,"A",[]],'
'[[2,3],4,q,"→E",[2,3]],[[1,2,3],5,q∧ ¬q,"∧I",[1,4]],[[1,2],6,¬p,"¬I",[3,5]]]')
rows = []
# split at ',' followed by two closing ]]
for x in re.split(r"(?<=\]\]),", s[1:-1]):
# split at ',' after closing ] OR between '"' and opening [
left, middle, right = re.split(r"(?<=\]),(?=\d)|(?<=\"),(?=\[)", x[1:-1])
# split the middle part at ','
middle = middle.split(",")
rows.append([literal_eval(left), *middle, literal_eval(right)])
df = pd.DataFrame(rows, columns=['Assumptions', 'Index', 'Proposition', 'Premisses', 'Rule'])
df["Index"] = df.Index.astype(int)
df["Premisses"] = df.Premisses.str.strip('"')
Result:
Assumptions Index Proposition Premisses Rule
0 [1] 1 ¬q A []
1 [2] 2 p→q A []
2 [3] 3 p A []
3 [2, 3] 4 q →E [2, 3]
4 [1, 2, 3] 5 q∧ ¬q ∧I [1, 4]
5 [1, 2] 6 ¬p ¬I [3, 5]
CodePudding user response:
This solution does not require Regex
import pandas as pd
s = '[[[1],1,¬q,"A",[]],[[2],2,p→q,"A",[]],[[3],3,p,"A",[]],[[2,3],4,q,"→E",[2,3]],[[1,2,3],5,q∧ ¬q,"∧I",[1,4]],[[1,2],6,¬p,"¬I",[3,5]]]'
s1 = s[2:-2].split('],[')
result = []
for item in s1:
lst = []
group = False
temp = ''
for e in item:
#extract group with square brackets `[ ]`
if e == '[':
group = True
temp = ''
elif e == ']' and temp[-1] != ']':
temp = e
lst.append(temp)
group = False
temp = ''
if group == True:
temp = e
elif e != ']':
#below non-group, to extract string between commas `,`
if e == ',' and temp != '':
lst.append(temp)
temp = ''
elif e != ',' and e != '"':
temp = e
result.append(lst)
df = pd.DataFrame(result, columns=['Assumptions', 'Index', 'Proposition', 'Premisses', 'Rule'])
print(df)
Assumptions Index Proposition Premisses Rule
0 [1] 1 ¬q A []
1 [2] 2 p→q A []
2 [3] 3 p A []
3 [2,3] 4 q →E [2,3]
4 [1,2,3] 5 q∧ ¬q ∧I [1,4]
5 [1,2] 6 ¬p ¬I [3,5]