I would like to get the following information
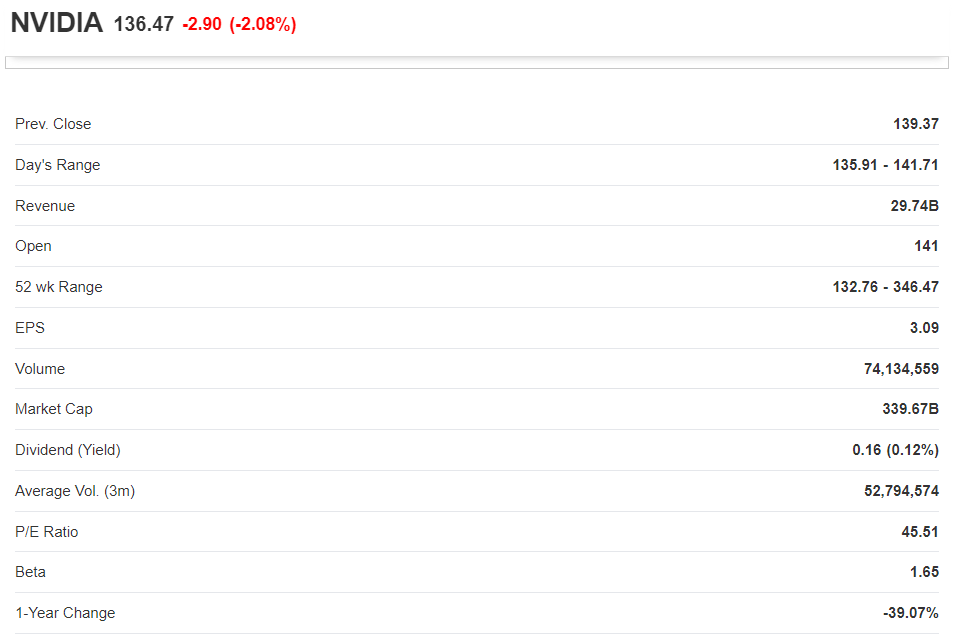
from Investing.com.
Code so far:
from selenium import webdriver
from bs4 import BeautifulSoup
import pandas as pd
driver = webdriver.Chrome(path)
driver.get("https://www.investing.com/equities/nvidia-corp")
content = driver.page_source
soup = BeautifulSoup(content, features="html.parser")
#get the element
soup.find('span', attrs={'class': 'key-info_dd-numeric__2cYjc',
}).text
returns 139.37, which is the value of prev.close.
How can I extend the code to get the remaining values? 135.91 -141.71 for Day's Range, 29.74B for Revenue, ..?
Looking at inspect, each of these seem to be under the same span class.
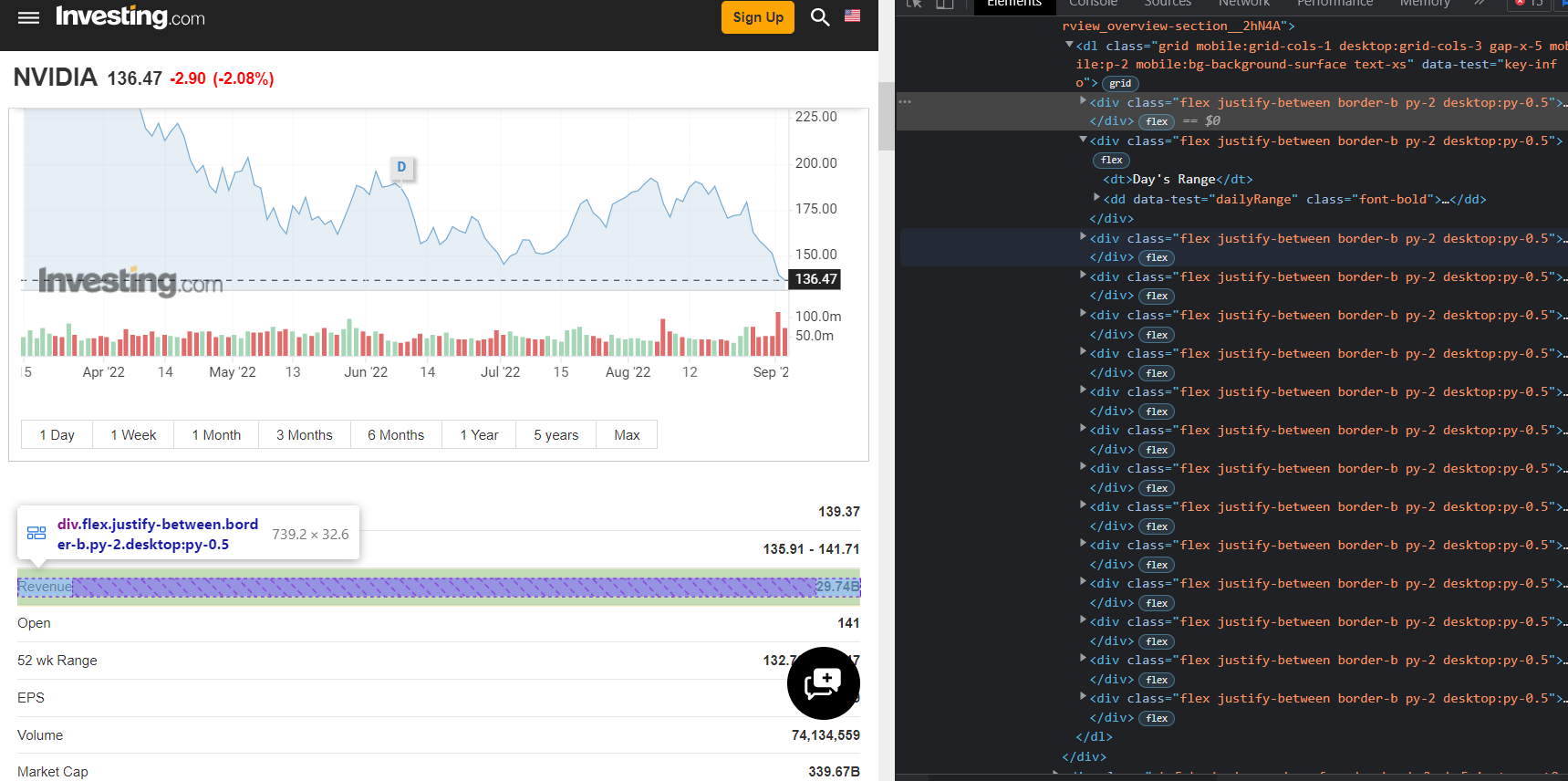
With a for loop,
for element in soup.find_all('div', attrs={'class': 'flex justify-between border-b py-2 desktop:py-0.5'}):
print(soup.find('span', attrs={'class': 'key-info_dd-numeric__2cYjc'
}).text)
I get 139.37 for as many as the items there:
139.37
139.37
139.37
139.37
139.37
....
139.37
Printing the element of the find_all:
for element in soup.find_all('div', attrs={'class': 'flex justify-between border-b py-2 desktop:py-0.5'}):
#print(soup.find('span', attrs={'class': 'key-info_dd-numeric__2cYjc'}).text)
print('')
print(element)
results in:
<div ><dt>Prev. Close</dt><dd data-test="prevClose"><span ><span>139.37</span><span></span></span></dd></div>
<div ><dt>Day's Range</dt><dd data-test="dailyRange"><span ><span>135.91</span><span></span></span><span >-</span><span ><span>141.71</span><span></span></span></dd></div>
<div ><dt>Revenue</dt><dd data-test="revenue"><span ><span>29.74</span><span>B</span></span></dd></div>
<div ><dt>Open</dt><dd data-test="open"><span ><span>141</span><span></span></span></dd></div>
<div ><dt>52 wk Range</dt><dd data-test="weekRange"><span ><span>132.76</span><span></span></span><span >-</span><span ><span>346.47</span><span></span></span></dd></div>
<div ><dt>EPS</dt><dd data-test="eps"><span ><span>3.09</span><span></span></span></dd></div>
<div ><dt>Volume</dt><dd data-test="volume"><span ><span>74,134,559</span><span></span></span></dd></div>
<div ><dt>Market Cap</dt><dd data-test="marketCap"><span ><span>339.67</span><span>B</span></span></dd></div>
<div ><dt>Dividend (Yield)</dt><dd data-test="dividend"><div ><span ><span>0.16</span><span></span></span><div ><span>(</span><span ><span>0.12</span><span>%</span></span><span>)</span></div></div></dd></div>
<div ><dt>Average Vol. (3m)</dt><dd data-test="avgVolume"><span ><span>52,794,574</span><span></span></span></dd></div>
<div ><dt>P/E Ratio</dt><dd data-test="ratio"><span ><span>45.51</span><span></span></span></dd></div>
<div ><dt>Beta</dt><dd data-test="beta"><span ><span>1.65</span><span></span></span></dd></div>
<div ><dt>1-Year Change</dt><dd data-test="oneYearReturn"><span ><span>-39.07</span><span>%</span></span></dd></div>
<div ><dt>Shares Outstanding</dt><dd data-test="sharesOutstanding"><span ><span>2,489,000,000</span><span></span></span></dd></div>
<div ><dt>Next Earnings Date</dt><dd data-test="nextEarningDate"><a data-test="link-key-info" href="/equities/nvidia-corp-earnings">Nov 17, 2022</a></dd></div>
CodePudding user response:
Try:
import requests
from bs4 import BeautifulSoup
url = "https://www.investing.com/equities/nvidia-corp"
soup = BeautifulSoup(requests.get(url).content, "html.parser")
out = {}
for dt in soup.select("dt"):
k = dt.get_text(strip=True)
v = dt.find_next("dd").get_text(strip=True)
out[k] = v
print(out)
Prints:
{
"Prev. Close": "139.37",
"Day's Range": "135.91-141.71",
"Revenue": "29.74B",
"Open": "141",
"52 wk Range": "132.76-346.47",
"EPS": "3.09",
"Volume": "74,134,559",
"Market Cap": "339.67B",
"Dividend (Yield)": "0.16(0.12%)",
"Average Vol. (3m)": "52,794,574",
"P/E Ratio": "45.51",
"Beta": "1.65",
"1-Year Change": "-39.07%",
"Shares Outstanding": "2,489,000,000",
"Next Earnings Date": "Nov 17, 2022",
}