I have data frame which looks similar to the one mentioned below:
a = dict({'Id' : [1, 2, 3, 4, 5, 6],
'Age' : [20, 30, 40, 50, 60, 70],
"Class" : [1, 2, 3, 4, 5, 6],
"test_0_n" : [1, 2, 0, 0, 4, 5],
"test_1_n" : [2, 2, 0, 0, 4, 5],
"test_2_n" : [3, 2, 0, 1, 4, 5],
"test_3_n" : [4, 3, 0, 0, 4, 5],
"test_4_n" : [5, 4, 0, 1, 8, 5],
"test_5_n" : [6, 4, 0, 0, 9, 5],
"test_6_n" : [7, 2, 0, 1, 10, 5],
"Output" : [21, 32, 999, 54, 65, 76]
})
test = pd.DataFrame(a)
test.head(10)
I want to do a sum of all the column containing "test" as column name and then calculate the sum of all those columns and if sum(axis = 1) is 0 Output = 999 else Output = Age Class.
In my code as you can see for Index = 2 Output is showing 999 because sum(axis=1) for all the columns with "test" is 0?
CodePudding user response:
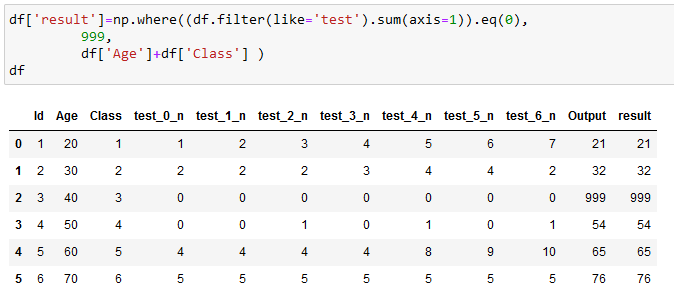
df['result']=np.where((df.filter(like='test').sum(axis=1)).eq(0),
999,
df['Age'] df['Class'] )
df
Id Age Class test_0_n test_1_n test_2_n test_3_n test_4_n test_5_n test_6_n Output result
0 1 20 1 1 2 3 4 5 6 7 21 21
1 2 30 2 2 2 2 3 4 4 2 32 32
2 3 40 3 0 0 0 0 0 0 0 999 999
3 4 50 4 0 0 1 0 1 0 1 54 54
4 5 60 5 4 4 4 4 8 9 10 65 65
5 6 70 6 5 5 5 5 5 5 5 76 76
notebook screeshot